GitHub Actions Runners: From Bottleneck to Full Automation
TL;DR: Our free GitHub Actions Runners minutes ran out within 5–10 days every month. We moved through four stages — free-tier runners → self-hosted EC2 → ephemeral Spot Instance runners via Terraform → Lambda-powered auto-switcher. End result: pipeline time dropped from 20 min to 12 min, parallel pipeline wait went from 15+ min to just 1–2 min, and we’ve had zero manual runner interventions since.
If you are a Head of Engineering or DevOps Lead at a 10–30 engineer team, your GitHub Actions Runners free minutes are probably running out by day 10 of every month — and someone on your team is fixing it manually. We have seen this in almost every mid-size team we work with.
That was us too. Our runners started failing — not because of bad code, but because we had burned through our free minutes in just 5–10 days. Pipelines stopped mid-run. Developers were blocked. And someone had to fix it manually every single month.
At Madgical Techdom, we have been through that cycle ourselves, and this blog is the full account of how we got out of it — and built a system that has required zero manual runner intervention since.
In this blog, we’ll walk through how we evolved our GitHub Actions runner strategy from a simple free-tier setup to a fully automated, cost-aware hybrid runner system.
We’ll break down:
- Why GitHub-hosted runners become a bottleneck
- How self-hosted EC2 runners introduced a new problem
- Why ephemeral runners changed the game
- How we automated runner selection using AWS Lambda, EventBridge, and SSM
Let’s dive in.
Why GitHub Actions Free Runners Become a Bottleneck
GitHub-hosted runners (ubuntu-latest) are excellent for getting started:
- No setup required
- Fully managed by GitHub
- Fast startup times
But they come with one critical constraint: limited free usage minutes.
Once those minutes are exhausted:
- Workflows stop or fail mid-pipeline
- Teams scramble to manually fix CI/CD
- Manual switching between runner types becomes necessary
For small projects, this feels manageable. For growing teams running multiple pipelines daily, it quickly becomes a serious productivity bottleneck.
Within just 5–10 days of the month, our pipelines would stop executing, get blocked, and require manual intervention. That is not acceptable in a production engineering environment.
The Challenge: One Problem Solved, Another Created
At Madgical Techdom, our engineering team was running multiple CI/CD pipelines for services including internal dashboards, automation tools, and deployment workflows.
All of these pipelines relied on GitHub-hosted runners with dynamic free-minute limits.
The team initially took the straightforward approach:
- Use
ubuntu-latestfor all workflows - Accept the free-minute limit as a constraint
- Manually switch to self-hosted runners when the limit was hit
But as the team and pipeline count grew, reality hit hard.
- Engineers had to monitor usage manually
- Pipelines failed without warning mid-month
- Manual runner switching didn’t scale across teams
The core question became:
Can we have reliable, cost-optimized GitHub Actions runners without manual intervention?
The Solution: A Phased Evolution of Runner Strategy
The DevOps team at Madgical Techdom took a phased approach to solving this problem — each phase fixing the previous one’s weakness.
The journey went through four distinct stages:
- Static GitHub-hosted runners → Free minute limits
- Self-hosted EC2 runners → Queue bottlenecks
- Ephemeral runners via Terraform → Parallel execution
- Automated hybrid runner selection → Full automation
Phase 1: Moving to Self-Hosted Runners on EC2
What We Did
To solve the cost problem, we provisioned a dedicated EC2 instance as a self-hosted GitHub runner, scheduled to run only during office hours (9 AM to 8 PM).
What Improved
- No dependency on GitHub free minutes
- Predictable and controllable infrastructure cost
- Consistent runner availability during working hours
What Broke Next
A single EC2 runner introduced a new bottleneck: queue delays.
With only one runner available:
- Multiple CI/CD jobs queued behind each other
- Parallel execution became impossible
- Developers waited for builds to complete before the next could start
CI/CD was slow again — just in a different way.
Phase 2: Ephemeral Runners Using Terraform
What We Did
We integrated the terraform-aws-github-runner module to provision ephemeral runners — runners created per job and destroyed upon completion. To keep costs low, we used AWS Spot Instances for runner provisioning, which significantly reduced EC2 compute costs compared to On-Demand pricing. This is a pattern we implement regularly as part of our DevOps infrastructure engagements.
How It Works
Instead of one static runner handling all jobs sequentially:
- A new runner is created automatically when a job starts
- The runner executes the job in an isolated environment
- The runner is destroyed immediately after job completion
What Improved
- No more queue bottleneck — previously, a second CI/CD pipeline had to wait for the first to finish before it could start. Now, each job gets its own fresh runner with only 1–2 minutes of initialization time for the new EC2 instance.
- Full parallel execution across all jobs simultaneously
- Better resource utilization — pay only for active compute, using Spot pricing
- Fully automated infrastructure via Terraform
Before this change, a developer pushing two pipelines back-to-back would wait the entire duration of the first pipeline before the second could even begin. After ephemeral runners, that wait dropped to just the 1–2 minute EC2 startup time — regardless of how many pipelines were running in parallel.
Now CI/CD scaled dynamically with demand.
Phase 3: Hybrid Strategy — Cost + Performance Optimization
The Insight
Even with ephemeral self-hosted runners working well, one question remained:
Why spin up self-hosted infrastructure when GitHub-hosted runners are still free?
We built a hybrid runner strategy that uses GitHub-hosted runners when free minutes are available, and automatically switches to self-hosted EC2 runners when the limit is reached.
Runner Decision Table
| Condition | Runner Used |
|---|---|
| Free minutes available | GitHub-hosted (ubuntu-latest) |
| Free minute limit reached | Self-hosted EC2 |
Implementation
Instead of hardcoding the runner in every workflow:
runs-on: ubuntu-latestWe switched to a dynamic expression:
runs-on: ${{ fromJson(vars.RUNNER_LABEL || '["ubuntu-latest"]') }}Now, runner selection is controlled by a GitHub variable — which can be updated programmatically without touching any workflow files.
Phase 4: Automating Runner Selection — The Real Game-Changer
Manual switching still didn’t scale. Even with the dynamic variable approach, someone had to decide when to switch and update the variable.
We built a fully automated runner selection system using AWS services.
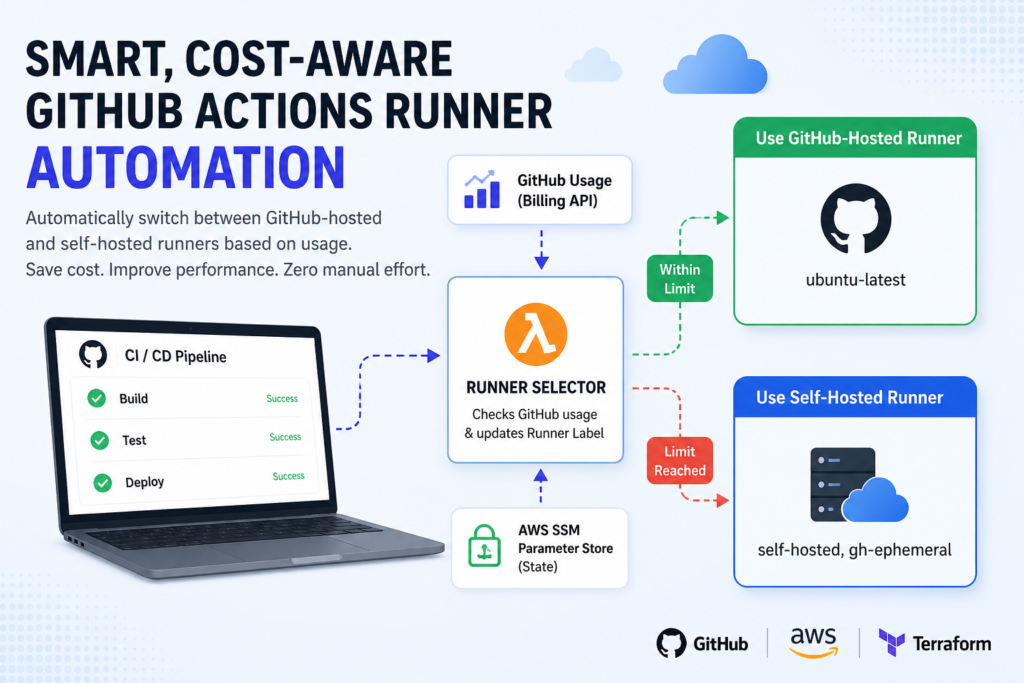
Architecture Overview
EventBridge (Cron Rules)
↓
AWS Lambda (Decision Engine)
↓
SSM Parameter Store (State)
↓
GitHub Billing API
↓
Update RUNNER_LABEL (GitHub Variable)
↓
GitHub Actions (dynamic runs-on)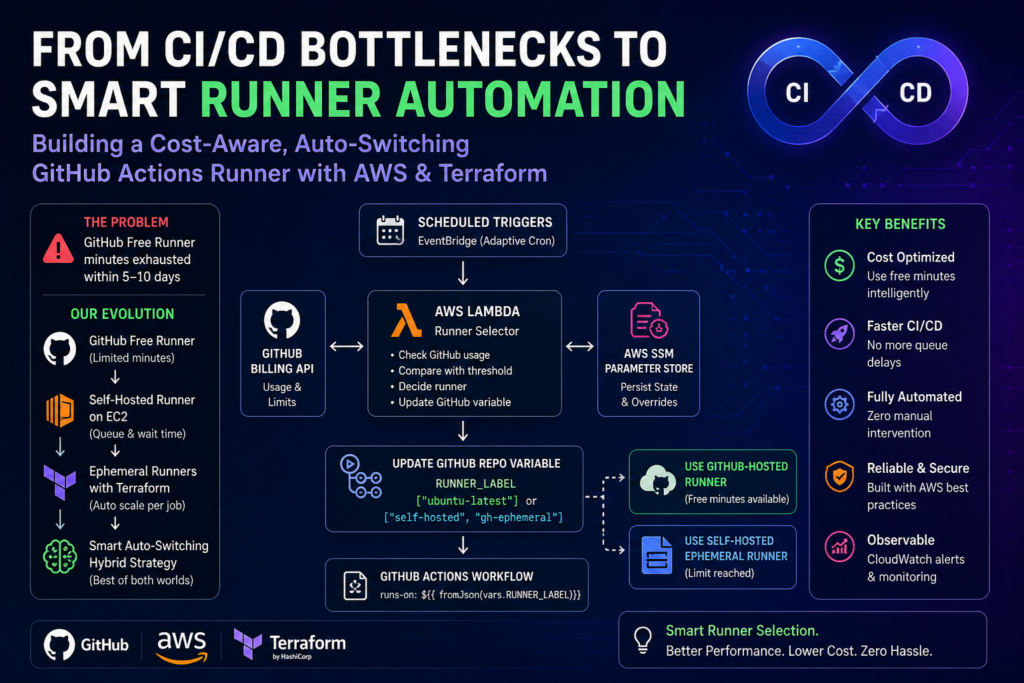
How the System Works
1. Usage Monitoring
A Lambda function calls the GitHub Billing API on a scheduled basis to track the current free-minute usage percentage.
2. Decision Logic
| Condition | Runner Selected |
|---|---|
| Usage < 80% threshold | GitHub-hosted |
| Usage ≥ 80% threshold | Self-hosted EC2 |
| API failure | Self-hosted (safe fallback) |
| Month start (1st) | GitHub-hosted (automatic reset) |
3. Adaptive Polling
To minimize unnecessary API calls, the polling frequency adapts based on the time of month:
| Days of Month | Polling Frequency |
|---|---|
| 1–15 | Daily |
| 16–25 | Every 6 hours |
| 26–31 | Every 2 hours |
4. Early Exit Strategy
Once the free-minute limit is reached:
- The system switches to self-hosted runners
- API polling stops for the rest of the month
This results in approximately 99% fewer API calls — and here is why that number is significant.
Before this architecture, the runner label switching logic ran directly inside the GitHub Actions workflow on a ubuntu-latest runner. This meant that every single CI/CD run triggered a call to the GitHub Billing API to check free-minute usage and update the RUNNER_LABEL variable accordingly.
There were two critical problems with this approach:
- It created a circular dependency — when the free-minute limit was exhausted, the workflow that was supposed to switch runners was itself running on a GitHub-hosted runner. So when the limit hit, the switching logic failed too, leaving teams stuck.
- API calls were wasteful — every pipeline run, regardless of time of month or usage level, made an API call to check usage.
After moving the decision logic to AWS Lambda, the API is called only on a scheduled basis (daily early in the month, every few hours near month-end). Once the limit is reached, polling stops entirely. No pipeline run ever touches the Billing API again until the next month.
5. Monthly Reset
On the 1st of each month, the system automatically resets to GitHub-hosted runners based on the calendar date — no API call needed.
Security and Reliability Design
- GitHub API token → stored in AWS Secrets Manager
- Runner state → stored in AWS SSM Parameter Store
- Monitoring and alerts → CloudWatch + SNS
Manual Override (Operational Control)
For debugging or testing purposes, the system supports a manual override via SSM:
# Force GitHub-hosted runners
aws ssm put-parameter --name /runner-switcher/override --value 'ubuntu-latest'
# Force self-hosted runners
aws ssm put-parameter --name /runner-switcher/override --value 'self-hosted'This gives the team full operational control when needed without bypassing the automated system.
Architecture Evolution Summary
| Stage | Problem | Solution |
|---|---|---|
| GitHub-hosted runners | Free minute limits | Move to self-hosted EC2 |
| Single EC2 runner | Queue delays | Ephemeral runners via Terraform |
| Ephemeral runners only | Cost inefficiency | Hybrid model |
| Hybrid with manual switching | Doesn’t scale | Full automation via Lambda |
Optional Optimization: Custom AMI (Advanced)
For teams with advanced performance requirements, we also created a custom EC2 AMI with pre-installed dependencies baked in.
This eliminates the time spent installing packages during each runner startup, resulting in noticeably faster CI/CD execution.
This optimization is most valuable when:
- Runner startup time is a bottleneck
- The same set of tools is installed in every run
- Jobs are frequent and short
Results: Before vs. After
Here is what changed in measurable terms after implementing the full hybrid automation system:
| Metric | Before | After |
|---|---|---|
| CI/CD pipeline execution time | ~20 minutes | ~12 minutes |
| Wait time for parallel pipelines | Full duration of first pipeline | 1–2 minutes (EC2 init only) |
| GitHub Billing API calls per month | One per every CI/CD run | Scheduled only (daily → hourly near month-end) |
| API call reduction | — | ~99% fewer calls |
| Manual runner intervention | Required every 5–10 days | Zero |
| Runner cost model | On-Demand EC2 | Spot Instances (significant cost reduction) |
| Monthly CI/CD infra spend | ~$120–150/month | ~$35–45/month (~70% reduction) |
The pipeline time improvement from 20 minutes to 12 minutes came from a combination of ephemeral runner isolation (no shared state or dependency conflicts from previous runs) and the custom AMI with pre-installed dependencies, which eliminated repeated package installation steps.
The most impactful change for developer experience was parallel pipeline handling. Previously, if two engineers pushed at the same time, one waited for the entire first pipeline to complete — often 15–20 minutes of idle time. Now, both pipelines start within 1–2 minutes of each other, each on a fresh dedicated runner.
This eliminates the time spent installing packages during each runner startup, resulting in noticeably faster CI/CD execution.
This optimization is most valuable when:
- Runner startup time is a bottleneck
- The same set of tools is installed in every run
- Jobs are frequent and short
Lessons Learned
1. The biggest mistake is solving cost before solving throughput
We did this ourselves. Fixing the free-minute problem with a single EC2 runner felt like progress — until it created a queue that was just as painful. A complete solution has to address cost and parallelism at the same time, not sequentially.
2. Single runners are a bottleneck in disguise
A single runner looks like a solution until your team grows past two or three engineers pushing regularly. Parallelism is non-negotiable in any real CI/CD environment. If your architecture cannot run two jobs simultaneously, it will fail you at the worst possible moment.
3. Ephemeral infrastructure is the only pattern that scales cleanly
Create → Use → Destroy. Every runner that persists between jobs carries risk — leftover state, conflicting dependencies, unpredictable behaviour. Ephemeral runners eliminate all of that by design. This is what resilient CI/CD infrastructure looks like in practice: no shared state, no cascading failures, no manual recovery.
4. If a human is making a recurring decision, that decision should be automated
Manual runner switching does not fail because people are careless. It fails because it is inherently unscalable. The moment a process requires a human to check something and act on it regularly, it needs to be automated — full stop.
5. Hybrid beats pure self-hosted every time
Running self-hosted runners for everything is wasteful when GitHub is giving you free minutes at the start of every month. A hybrid approach that uses managed runners when free and switches automatically to self-hosted when needed is always the smarter architecture.
When Should You Use This Architecture?
This architecture is most valuable for product teams of 5–30 engineers who are shipping multiple services daily and starting to feel the coordination cost of shared CI/CD infrastructure. If your pipelines are competing for the same runner, your free minutes are gone before mid-month, and someone on your team is manually fixing CI/CD regularly — this is built for you.
Use this approach if:
- Your GitHub free minutes are exhausted within the first two weeks of the month
- You run multiple parallel CI/CD pipelines across teams or services
- You want cost optimization and performance solved together, not separately
- You manage infrastructure via Terraform and AWS
This architecture may be more than needed if:
- Your pipelines are infrequent or low-volume
- You are a solo developer or very small team
- You do not use AWS as your cloud provider
Is Your CI/CD Pipeline Costing You More Than It Should?
If your team is burning through GitHub minutes, dealing with queued pipelines, or manually switching runners — these are symptoms of an infrastructure problem, not a process problem.
At Madgical Techdom, we run this as a 2–3 week fixed-scope DevOps audit-and-build engagement. You get the full automation layer deployed, documented, and handed off to your team — ready to run without ongoing maintenance.
We identify where runners cost you time and money, design the hybrid automation layer, implement it with Terraform and Lambda, and hand it off with full documentation.
Book a 30-min call with Kapil, and we will assess your current setup in the first session.
The Bigger Pattern
This is the same systems-thinking approach we apply across all our engagements — whether it is CI/CD runners, Azure tenant provisioning (reduced from 4 hours to 20 minutes), or AI-driven operational automation.
The principle is always the same: identify the recurring human decision, automate it, and design for cost-awareness from day one. CI/CD infrastructure is one surface. The same pattern scales to data pipelines, agentic workflows, and legacy system integration.
Building resilient teams that deliver quality while maintaining speed — that is what this work is actually about, whether the problem is a runner queue or an enterprise deployment bottleneck.
Explore our full DevOps and automation services if you want to see how this thinking applies beyond CI/CD.
Final Thoughts
GitHub Actions Runners should never be something developers think about. CI/CD pipelines should be fast, reliable, cost-efficient, and require zero manual intervention.
What started as a GitHub minutes problem at Madgical Techdom turned into a full-scale redesign of our runner infrastructure.
Today, our system is:
- Dynamic — runner selection adapts to usage automatically
- Scalable — ephemeral runners handle any parallel workload
- Cost-aware — free minutes are maximized before self-hosted kicks in
- Fully automated — no human intervention required
Most importantly: developers never think about runners anymore.
If you are still hardcoding ubuntu-latest, manually switching runners, or waiting on queued jobs — it might be time to rethink your CI/CD runner architecture.
Thank you for reading! If this blog helped clarify how to evolve your GitHub Actions runner strategy, feel free to mention it in the comments below or contact us.
What stage of this journey is your team at right now? Still on free-tier runners, or already running something more complex? Drop it in the comments — we would love to hear how others are solving this.