Big Data – Hadoop and Hive 101: Everything You Need to Know
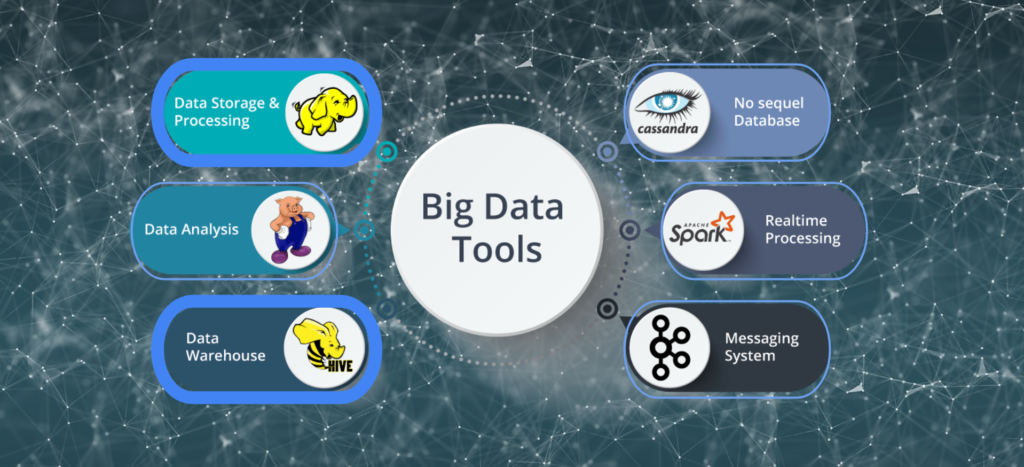
Hadoop & Hive in Big Data
Introduction
What comes to mind when you hear the term “big data”? Is there a lot of data there? Or is it complicated data? Is data of a variety of types? Or is it the daily increase in data rate? In such a case, you are right. Technology has integrated itself into every aspect of our lives. For instance, whether it is smartphones, laptops, or smart televisions, our dependency on various technologies and gadgets has increased.
In addition, they gather your data and use it to improve software and apps as much as possible. Above all, data can be gathered through databases, social media, the cloud, and the Internet of Things (IoT).
I’ll use Netflix as an example of an OTT platform. Netflix uses viewership and search data. This is done to suggest shows according to their preferences. Furthermore, Netflix also uses data from social media and browsers. In short, this is done to track user activity and interests.
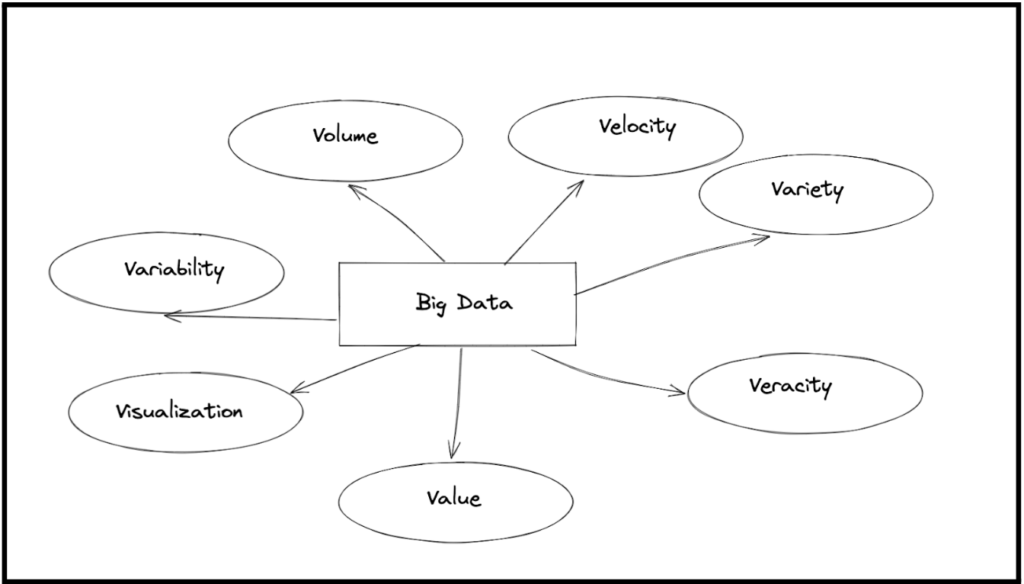
What is Big Data?
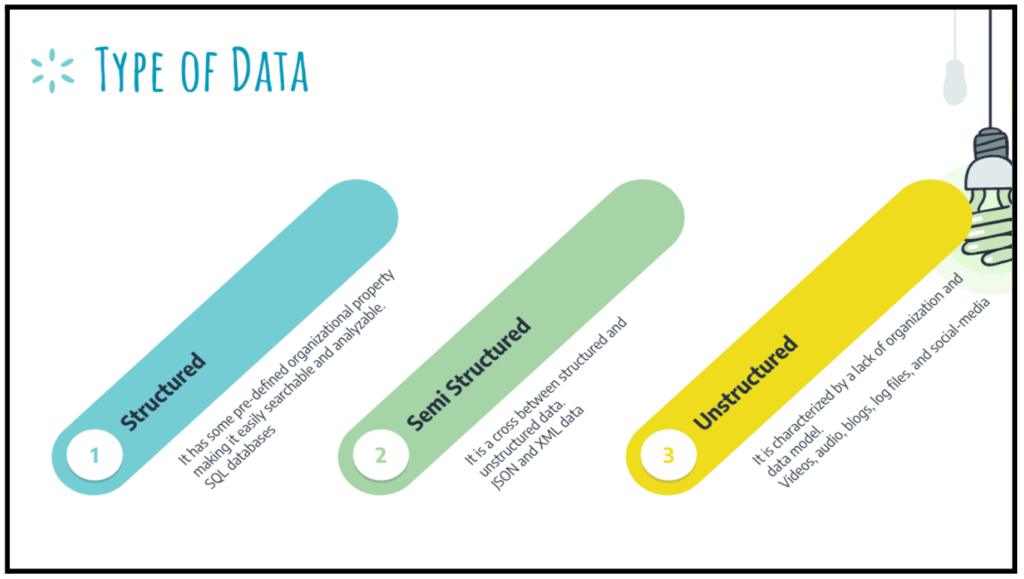
“Big data” refers to big, complicated data sets and volumes. Firstly, it is the collection of various kinds of data. Secondly, the data may be present in a variety of ways. For instance, text, text messages, bytes, Instagram photos, or YouTube videos. Importantly, the data can be of any type. For instance, structured, semi-structured, and unstructured.
We can identify big data by the amount of data, rate of data, and many types of data. Most importantly, these three characteristics can help you recognize big data.
What is Hadoop?
Google developed the open-source Hadoop software framework. It stores and processes massive amounts of unstructured data. In other words, the Hadoop framework is the software manifestation of big data. It stores and analyses massive volumes of data. Most importantly it is a distributed and scalable platform.
The lure of Hadoop is that it runs on cheap commodity hardware. On the other hand, its competitors may need expensive hardware to do the same job. Hadoop detects and handles failures at the application layer.
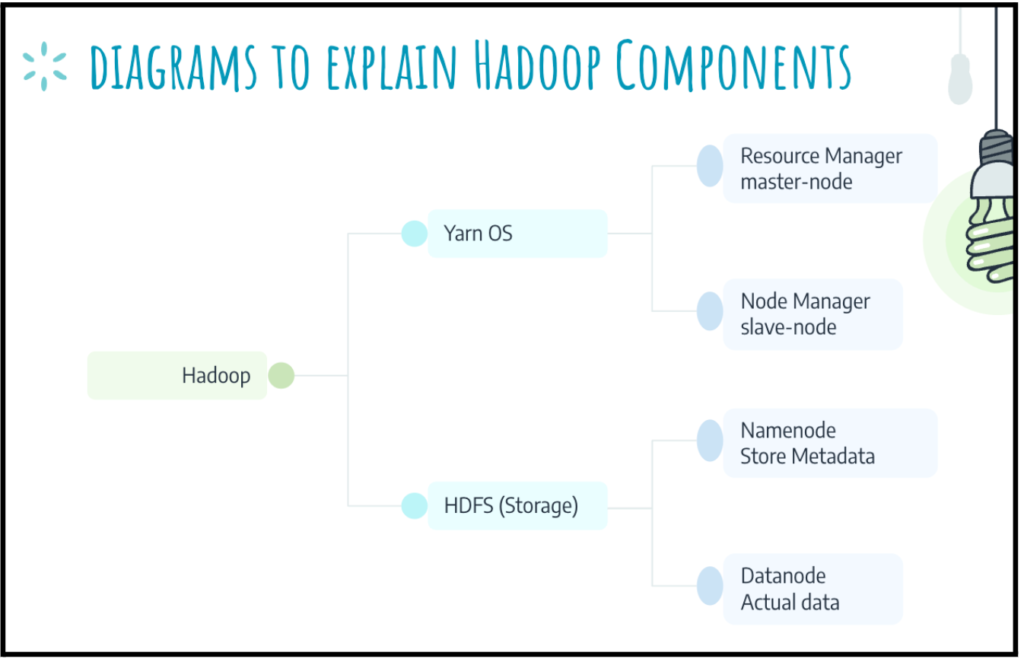
- YARN is analogous to an operating system for a cluster. YARN allocates cluster resources among competing jobs
- A cluster is a set of loose or tight connections among computers. They work together as a single system.
- Resource and Node Manager, work in a master-slave relationship. In this relationship, the Resource Manager (RM) is the master. On the other hand, the Node Manager is the slave.
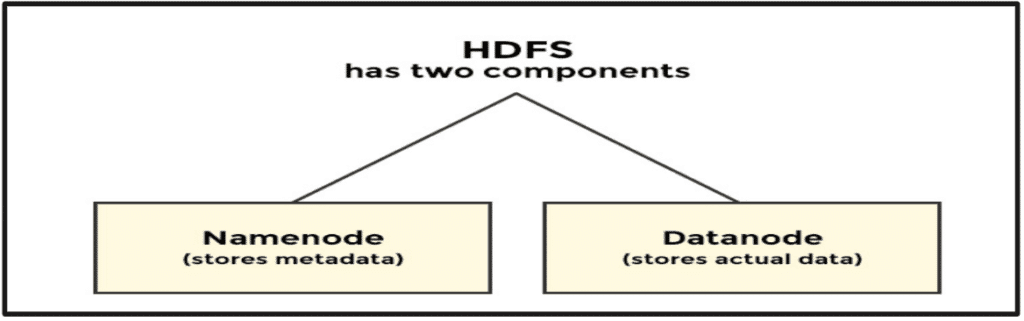
- HDFS is a file system. It provides a mechanism for storing, organizing, and retrieving data on a storage medium.
- Namenode maintains the filesystem tree and all metadata.
- Datanode stores the actual data.
What is MapReduce?
MapReduce is a programming model with an associated implementation. This method simultaneously creates and transmits huge data sets. Further, it is an implementation of the computing model introduced by Google. As certain systems perform data-parallel computations on clusters of unreliable machines.
MapReduce programming model:
- It is a distributed framework. And consists of clusters of commodity hardware that run maps or reduce tasks.
- The map and reduce tasks always work in parallel.
- Fault-tolerant: If any task fails, it reschedules on a different node.
- As the problem becomes bigger then more machines need to add to solve the problem. Therefore, the framework can scale horizontally rather than vertically.
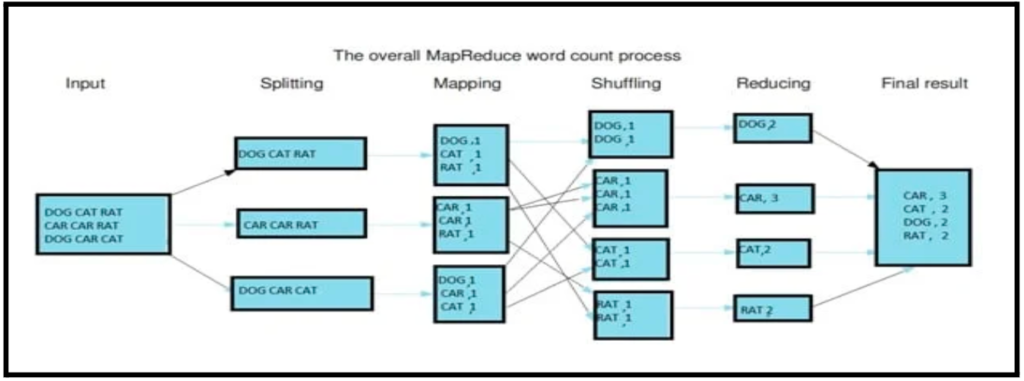
Phases of MapReduce
The model consists of two phases:
1. Map phase:
Maps transform input records into intermediate records. Moreover, the transformed records do not need to be the same type. Certainly, a given input key/value pair may map to zero or many output pairs.
2. Reduce phase:
Reducers decrease the intermediate key-value pairs from the map phase.
HDFS (Hadoop Distributed File System)
File system:
- A file system is a mechanism for storing, organizing, and retrieving data on a storage medium.
- There are several distributed file systems like GFS (Google File System).
The architecture of HDFS:
- Goles: Large files, streaming data access (write-once and read-many-times), and commodity hardware.
What is Hive?
Apache Hive is software that runs on a Hadoop cluster. The software helps manage data in a structured way. Importantly, it is one of the most popular data management tools for big data. The concept behind Hive is that you structure your data as tables. In addition, you can analyze the data using Hive Query Language. And run your analyses as Hive jobs, that’s it!
Important Features of Hive Hadoop
- Hive is designed for querying and managing only structured data stored in tables.
- Schema gets stored in a database. On the other hand, the processed data goes into a Hadoop Distributed File System.
Visit my GitHub page to learn more about Hive Query Language.
Conclusion
In conclusion, Hadoop and Hive are powerful tools for processing big data. Hadoop is an open-source framework that allows distributed processing of large datasets across clusters of computers, while Hive is a data warehouse infrastructure that provides SQL-like queries for Hadoop. Together, they offer a scalable and cost-effective solution for handling massive amounts of data.
As a beginner, understanding the basics of Hadoop and Hive is essential for efficiently processing and analyzing big data. The key components of Hadoop, including the Hadoop Distributed File System (HDFS) and MapReduce, provide a reliable and fault-tolerant framework for processing data in a distributed environment. Hive simplifies the data processing tasks by allowing users to use SQL-like queries on Hadoop.
However, mastering Hadoop and Hive requires continuous learning and practice to improve your knowledge and skills in these technologies.
References
- Excalidraw and Google Slides for creating images.
- Quillbot and Hemingway App for correcting my AIOSEO errors.
- educative, and Projectpro helped me understand the concepts.
- ChatGPT, and Writesonic for improving content.
- Visit my GitHub page to learn more about Hive Query Language.
- Contact us if you need help in data engineering.
One thought on “Big Data – Hadoop and Hive 101: Everything You Need to Know”
Comments are closed.
Thanks, Sunil for taking the time and effort on writing this blog. Firstly, you’ve provided a wealth of information in this blog post about Big Data using Hadoop and Hive. To put it simply, you have done an excellent job of breaking down difficult ideas into easily digestible chunks.
Secondly, your blog’s organisation makes it simple for readers to follow along and get the full picture. You’ve made excellent utilisation of headings, subheadings, and diagrams to present large amounts of information.
Thirdly, your writing style is clear and simple, which helped me quickly absorb the most important information.
Most importantly, your excitement for the topic and conversational style make this post more enjoyable. There is no doubting your commitment to Big Data and the depth of your knowledge in this area from reading your work.
Keep it up!
Everyone interested in Big Data, Hadoop, and Hive will find your blog post to be an invaluable resource. To many others, your post will serve as an invaluable resource because you have shared your knowledge and insight.