How to Build a Movie Recommendation System with AWS?

Introduction
Firstly, welcome to Madgical Techdom, where simplicity meets innovation in data-driven solutions. With a dedicated team of experts, we specialize in crafting bespoke technologies tailored to your business needs. Today, we’re excited to dive into the fascinating world of recommendation system, focusing on how our team has transformed the user experience for OTT platforms. By leveraging scalable infrastructure and cutting-edge tools like AWS and the Gorse recommendation engine, we’ve built a solution that brings customized content to each viewer’s screen.
In the rapidly evolving landscape of online streaming, OTT platforms face a big challenge: keeping users engaged. With thousands of movies and shows at their disposal, viewers are often overwhelmed by choice. Ever spent more time scrolling than actually watching? That’s exactly the problem. Users struggle to discover content that truly resonates with their unique tastes. Without a robust recommendation system, platforms risk losing users who simply can’t find something that catches their eye. This struggle to maintain engagement is a critical problem that many platforms, especially those dealing with large datasets, are trying to solve.
At Madgical Techdom, we took on this challenge head-on by developing a scalable, high-performance movie recommendation system. Using AWS for data management and Gorse for personalization, we built an efficient ETL pipeline to seamlessly transfer data from Amazon RDS to our recommendation engine. With AWS Glue transforming raw data into actionable insights, and Gorse analyzing user interactions and feedback, our solution not only suggests the right content but does so at scale, offering tailored recommendations to millions of users simultaneously.
The Technical Stack

To implement this system, we relied on several key technologies:
- AWS RDS: Amazon Relational Database Service (RDS) is a managed database service that simplifies the setup, operation, and scaling of relational databases in the cloud. It supports multiple database engines like MySQL, PostgreSQL, and Oracle, automates administrative tasks, and offers high availability, security, and performance, enabling seamless integration with other AWS services.
- AWS DMS: AWS Database Migration Service (DMS) helps migrate databases to AWS securely and efficiently with minimal downtime. It supports homogeneous and heterogeneous migrations, automatically handling conversion and data replication. AWS DMS is ideal for moving on-premises databases to Amazon RDS, Aurora, DynamoDB, and other AWS data stores.
- Amazon S3: Amazon S3 (Simple Storage Service) is a scalable object storage service that enables users to store and retrieve data anytime, anywhere. It’s designed for large-scale storage, offering features like data encryption, versioning, and lifecycle management, making it ideal for backups, content storage, and data lakes.
- AWS Glue: AWS Glue is our ETL (Extract, Transform, Load) service. It extracts the raw data from S3, transforms it into the required format for the recommendation engine, and loads it back into another S3 bucket or directly into the engine. Glue’s ability to handle complex data transformations with ease made it the backbone of our data pipeline.
- Gorse: Gorse is the open-source recommendation engine that powers our platform. It processes the transformed data and generates personalized content recommendations. Gorse supports collaborative filtering, content-based filtering, and hybrid models, giving us the flexibility to fine-tune recommendations based on different criteria.
Understanding the Data in a Movie Recommendation System

In a movie recommendation system, high-quality, diverse data is key to generating accurate, personalized suggestions. The three essential data types are user data, movie data, and feedback data, each stored in an S3 bucket for easy access and processing.
1. User Data
User data includes information about the users who interact with the platform, such as demographics (age, gender, location), watch history, and preferences. In a recommendation system, this data helps to understand user behavior and preferences. For instance, knowing that a user often watches action movies can help in suggesting similar genres.
Key Attributes:
- user_id: Unique identifier for the user
- ItemLabels: Unique labels of items liked by the user
- Labels: Concatenated user details (Age, Gender, Occupation, Zip) and item labels
- FinalLabels: Combined user details and item labels as a string
2. Movie Data
Movie data refers to metadata about the movies available on the platform. This includes information such as movie titles, genres, directors, cast, release dates, and ratings. Movie data is essential for content-based filtering, where recommendations are made based on the attributes of the movies a user has liked or watched.
Key Attributes:
- movie_id: Unique identifier for the movie
- movie_title: Title of the movie
- release_date: Release date of the movie (formatted)
- Labels: Concatenated string of genres
3. Feedback Data
Feedback data captures user interactions with the platform, such as ratings, reviews, likes, and watch history. This data is the backbone of collaborative filtering algorithms, where the system recommends movies based on the preferences of similar users.
Key Attributes:
- FeedbackType: ‘like’ if the rating is 4 or higher, otherwise ‘unlike’
- user_id: Unique identifier for the user
- item_id: Unique identifier for the movie
- Timestamp: Formatted timestamp
By efficiently storing and processing this data, the recommendation system delivers personalized movie suggestions that align with each user’s unique tastes.
Storing Data in AWS RDS

In our movie recommendation system, managing and storing data efficiently is crucial for delivering accurate and personalized suggestions. AWS RDS (Relational Database Service) provides a robust and reliable platform to store user data, movie data, and feedback data in a structured format. Let’s explore how we utilize AWS RDS and AWS DMS (Database Migration Service) to manage our data and keep our recommendation engine up-to-date.
Structuring Data in AWS RDS
Our data is organized into three key tables:
- User Data Table: Contains user details (
user_id,ItemLabels, andLabels) to capture demographic and preference information, essential for creating personalized recommendations. - Movie Data Table: Stores movie metadata (
movie_id,movie_title,release_date, andGenres) for content-based filtering. - Feedback Data Table: Logs user interactions like ratings and reviews, using columns such as
FeedbackType,user_id,item_id, andTimestamp, which are vital for collaborative filtering.
Migrating Data with AWS DMS
AWS DMS ensures seamless migration and continuous synchronization of data from RDS to S3. Here’s how it works:
- Initial Data Migration: AWS DMS extracts data from the user, movie, and feedback tables, transforms it into CSV format, and stores it in designated S3 folders (e.g.,
s3://your-bucket/user_data). - Ongoing Synchronization: DMS monitors the RDS tables for updates. Any new data, such as added movies or user interactions, triggers an automatic CSV generation and is stored in the respective S3 folder.
Advantages of AWS RDS
Using AWS RDS to manage our data offers several key advantages:
- Security: AWS RDS provides advanced security features, including encryption at rest and in transit, IAM integration, and automated backups, ensuring that our sensitive data is well-protected.
- Scalability: RDS allows us to scale our database resources easily to accommodate growing data volumes, ensuring that our system can handle increased demand without compromising performance.
- Reliability: With automated backups, snapshots, and multi-AZ deployments, AWS RDS ensures high availability and durability, minimizing downtime and ensuring data integrity.
- Performance Optimization: RDS supports a variety of database engines and provides options for optimizing performance, such as read replicas and provisioned IOPS, which help us maintain fast and efficient data processing.
By leveraging AWS RDS and DMS, we can efficiently manage and synchronize our data, ensuring that our recommendation system remains accurate, secure, and scalable.
Storing Data in S3

In our movie recommendation system, managing data well is key to providing smooth processing and accurate suggestions. We use Amazon S3 (Simple Storage Service) to store and organize our data. Let’s break down how we structure and store different types of data in S3.
Organizing Data by Type
To keep things organized and easy to find, we create separate folders in the S3 bucket for each type of data. These folders are named clearly, like user_data/, movie_data/, and feedback_data/. This makes it simple to manage and retrieve data.
- User Data: This folder has information about user interactions, preferences, and demographics.
- Path:
s3://your-bucket/user_data - Description: Stores details like watch history and preferences, organized by date for easy access.
- Path:
- Movie Data: This folder contains metadata about the movies available, including titles, genres, and ratings.
- Path:
s3://your-bucket/movie_data - Description: Keeps all movie metadata in one or more files for easy searching and filtering.
- Path:
- Feedback Data: This folder captures user feedback, such as ratings, reviews, and likes.
- Path:
s3://your-bucket/feedback_data - Description: Records user interactions and feedback, organized by date for tracking behavior over time.
- Path:
Optimizing Access and Processing
Each folder in S3 can have multiple files, often divided by date or other criteria. This approach helps improve access and processing efficiency. By breaking data into smaller pieces, we make it quicker to retrieve and process information during the ETL (Extract, Transform, Load) pipeline.
Advantages of S3 Data Organization
- Scalability: The structure can handle growing datasets without slowing down performance.
- Efficiency: Partitioned files allow for faster retrieval and processing, especially with large amounts of data.
- Accessibility: Organized folders make data management easier, ensuring that data can be quickly accessed and processed throughout the recommendation system.
This smart organization of data in S3 helps our recommendation system work efficiently, ultimately delivering accurate and personalized movie suggestions to users.
Integrating the Gorse Recommendation System

To bring personalized recommendations to life, we integrate the Gorse recommendation system into our workflow. Gorse is an open-source recommendation engine designed to provide high-quality, scalable, and real-time recommendations based on user interactions and preferences.
What Makes Gorse Stand Out
Gorse excels in handling large datasets and delivering accurate recommendations by leveraging collaborative filtering and content-based algorithms. It uses user and movie data to create sophisticated models that predict which movies a user might enjoy based on their past behavior and preferences. This means that as users interact with the platform—whether by watching movies, rating them, or leaving reviews—Gorse continuously updates its recommendations to reflect their evolving tastes.
How Gorse Fits into Our Workflow:
After data is stored in S3, it is processed and transformed into the required format using AWS Glue. This data is then fed into Gorse, where it is used to generate personalized recommendations. By analyzing user behavior, movie attributes, and feedback, Gorse creates a tailored experience that keeps users engaged and coming back for more.
With Gorse, we can efficiently scale our recommendation system, ensuring users receive relevant and engaging movie suggestions that enhance their overall viewing experience.
Setting Up the AWS Environment for a Scalable Movie Recommendation System
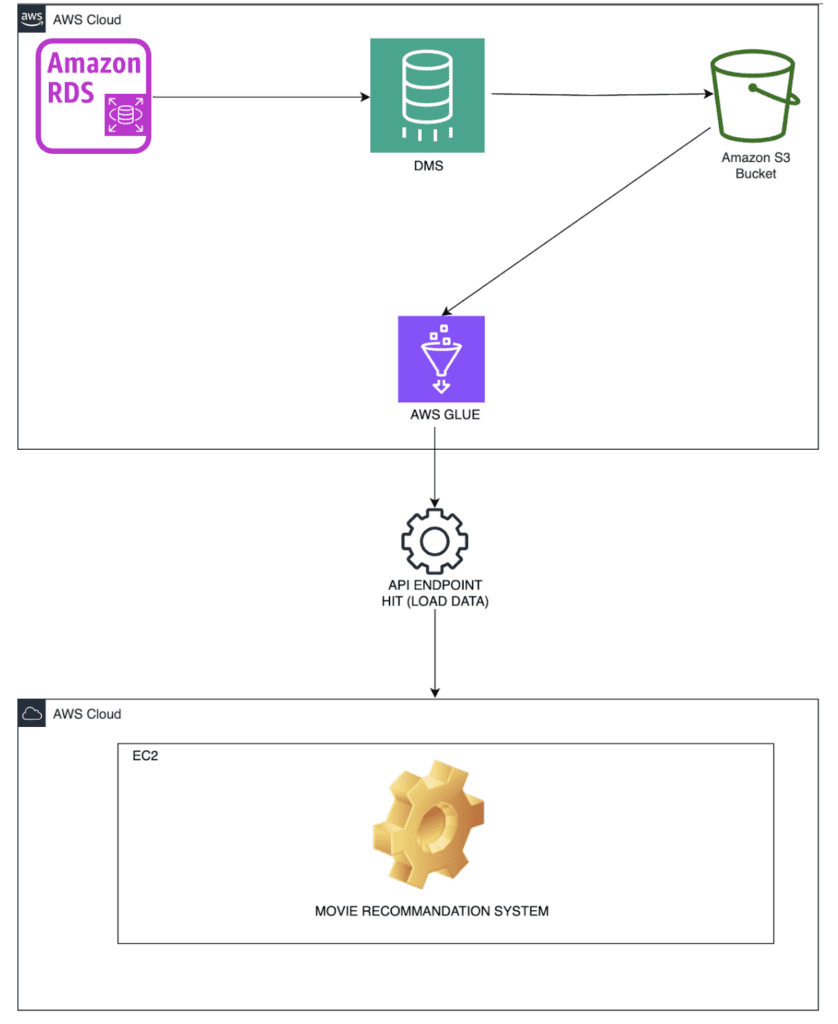
Building a scalable and secure movie recommendation system involves configuring several essential AWS services, including RDS, DMS, S3, EC2, AWS Glue, and IAM roles.
- Amazon RDS (Relational Database Service) is the primary storage for all structured data, such as user data, movie metadata, and feedback information. The data stored here is continuously updated, forming the foundation of the recommendation system.
- AWS DMS (Database Migration Service) plays a crucial role in keeping your recommendation system up-to-date. It links directly with the RDS tables, capturing any changes and automatically generating a CSV file with the updated data. This CSV file is then stored in Amazon S3, ensuring that the latest data is always available for processing.
- Amazon S3 (Simple Storage Service) serves as the central repository for all data, including the updated CSV files generated by DMS. Organizing your data into well-structured folders within S3 ensures easy management and access. Server-side encryption is utilized to maintain data security.
- AWS Glue is responsible for reading the updated data from S3 and transforming it according to the needs of the recommendation system. Glue’s ETL (Extract, Transform, Load) capabilities are leveraged to prepare the data in a format suitable for generating personalized movie recommendations.
- Amazon EC2 (Elastic Compute Cloud) is used to deploy the Gorse recommendation engine. The EC2 instance processes the transformed data and generates personalized recommendations based on user preferences and behaviors. Selecting the appropriate instance type and configuring it properly ensures optimal performance of the recommendation engine. Security groups are also set up to protect your EC2 instances and control access.
In summary, by effectively integrating RDS for data storage, DMS for automated data updates, S3 for centralized data management, AWS Glue for data transformation, and EC2 for deploying the Gorse recommendation system, you can build a robust, scalable, and efficient movie recommendation system that adapts to your users’ needs.
Automating the ETL Pipeline for Movie Recommendations

To ensure our movie recommendation system runs smoothly and efficiently, we need to automate the ETL (Extract, Transform, Load) pipeline. This process involves selecting the data source, transforming the data, creating a Glue job, inserting the data into Gorse via its API, and setting up a scheduler to keep everything updated. Here’s a step-by-step guide to automating this pipeline:
1. Selecting the Data Source
The first step in automating our ETL pipeline is to select the data source. In our case, this is Amazon S3, where we store various types of data such as user information, movie metadata, and feedback data. The S3 bucket is organized into folders by data type, which allows us to efficiently access and process the data. For example:
- User Data: s3://your-bucket/user_data/
- Movie Data: s3://your-bucket/movie_data/
- Feedback Data: s3://your-bucket/feedback_data/
By selecting S3 as our data source, we leverage its scalability and flexibility, which are essential for handling large volumes of data and ensuring reliable data retrieval.
2. Transforming the Data
Once the data is selected, the next step is to transform it into the required format. This involves cleaning, organizing, and structuring the data according to our needs. For example, user data might be formatted as CSV, Parquet, or JSON files, each containing records like user_id, ItemLabels, Labels, and FinalLabels. Similarly, movie data might include movie_id, movie_title, release_date, and genre information.
The transformation process involves:
- Parsing the raw data: Converting data from its raw form into a structured format.
- Filtering and cleaning: Removing irrelevant or erroneous data.
- Formatting: Ensuring consistency in the data format to align with the requirements of the recommendation engine.
3. Creating a Glue Job
With the data transformed, the next step is to create a Glue job. AWS Glue is a fully managed ETL service that simplifies the process of extracting, transforming, and loading data. Here’s how to set it up:
- Create a Glue Crawler: This crawler scans the data stored in S3, infers the schema, and creates tables in the AWS Glue Data Catalog.
- Define the Glue Job: Configure the Glue job to extract data from the S3 buckets, apply the necessary transformations, and load the processed data into the target format.
- Set Up the Job Schedule: Configure the Glue job to run at regular intervals, ensuring that data is continually updated and processed.
AWS Glue handles the heavy lifting of data transformation and loading, making it easier to maintain and scale the ETL pipeline.
4. Inserting Data into Gorse Using API
After transforming the data, it’s time to load it into the Gorse recommendation system. Gorse provides an API that allows us to insert and update data programmatically. The process involves:
- Prepare API Requests: Use the Gorse API to send HTTP requests with the transformed data. This typically includes user data, movie metadata, and feedback information.
- Update Data: Periodically send updated data to Gorse to ensure the recommendations reflect the most recent user interactions and content changes.
The API integration ensures that Gorse receives the latest data, enabling it to generate accurate and relevant recommendations.
5. Automating the Pipeline with a Scheduler
To maintain a seamless workflow, we automate the entire ETL pipeline using a scheduler. This scheduler orchestrates the data extraction, transformation, loading, and updating processes, ensuring that the recommendation system is always up-to-date. Here’s how to set it up:
- Define the Schedule: Configure the scheduler to trigger the ETL processes at regular intervals, such as daily or hourly.
- Monitor and Manage: Use monitoring tools to track the performance and success of the scheduled jobs. Address any issues promptly to ensure continuous operation.
By automating the ETL pipeline, we reduce manual intervention, minimize errors, and ensure that our recommendation system operates efficiently, providing users with timely and relevant movie suggestions.
Creating and Securing API Endpoints

In this section, we focus on setting up and securing API endpoints that will handle the processed data from our ETL pipeline. These endpoints are crucial for integrating the transformed data into the recommendation system, ensuring that data flows seamlessly between the processing layer and the recommendation engine.
Creating API Endpoints
The API endpoints serve as the bridge between the ETL pipeline and the Gorse recommendation system. These endpoints will receive the processed data, such as movie details, user feedback, and user profiles, and will pass this data to the recommendation engine for analysis and use.
Key considerations while creating these endpoints:
- Data Validation: Ensure that all incoming data is validated before processing to maintain data integrity.
- Error Handling: Implement robust error handling to manage any data inconsistencies or API failures, ensuring smooth operations.
Securing API Endpoints
Securing the API endpoints is vital to protect the data and the recommendation system from unauthorized access and potential threats. Here are some key practices to follow:
- Authentication: Implement strong authentication mechanisms, such as API keys or OAuth, to control access to the endpoints.
- Encryption: Use HTTPS to encrypt data in transit, protecting sensitive information from being intercepted.
- Rate Limiting: Set rate limits to prevent abuse or overload of the API, ensuring the service remains available to legitimate users.
- Access Control: Define roles and permissions to restrict access to the API based on the user’s role or level of authorization.
By carefully creating and securing these API endpoints, we ensure that the data processed by our ETL pipeline is safely and efficiently integrated into the Gorse recommendation system, enabling it to deliver personalized recommendations with confidence.
Testing and Monitoring the System

In this section, we delve into the importance of testing and monitoring the API endpoints and the overall recommendation system. Ensuring that the system functions correctly and efficiently is critical to delivering reliable and accurate recommendations to users.
Testing the System
Before deploying the API endpoints and the recommendation engine, thorough testing is essential to identify and resolve any potential issues. Here’s how to approach testing:
- Unit Testing: Test individual components of the API endpoints to ensure that each function behaves as expected. This includes validating data handling, error responses, and correct implementation of business logic.
- Integration Testing: Test the interaction between the ETL pipeline, API endpoints, and the recommendation engine. This helps to ensure that the data flows smoothly and that all components work together seamlessly.
- Load Testing: Simulate high traffic to test the system’s performance under stress. This will help identify bottlenecks and ensure the system can handle peak loads without degradation in service quality.
- Security Testing: Validate the security measures in place, such as authentication, encryption, and access control, to ensure that the system is secure from potential threats.
Monitoring the System
Continuous monitoring is vital to maintaining the health and performance of the system after deployment. Effective monitoring practices include:
- Performance Monitoring: Track key metrics such as response times, throughput, and error rates to ensure the system is performing optimally. Tools like AWS CloudWatch or Prometheus can be used to set up real-time monitoring and alerts.
- Error Tracking: Implement logging and error tracking to quickly identify and resolve any issues that arise. This helps in proactive maintenance and reduces downtime.
- API Usage Monitoring: Monitor API usage patterns to detect any unusual activity, which might indicate potential security threats or misuse of the system.
- Resource Monitoring: Keep an eye on resource usage, including CPU, memory, and network bandwidth, to ensure that the system is running efficiently and that resources are scaled appropriately as demand changes.
By rigorously testing and continuously monitoring the system, you can ensure that the recommendation engine remains reliable, secure, and capable of delivering high-quality recommendations to users.
Integration with OTT Platforms

Integrating a recommendation system like Gorse with existing OTT (Over-The-Top) platforms can significantly enhance the user experience by delivering personalized content suggestions based on viewing history, ratings, and preferences. However, this integration comes with its own set of challenges that need to be addressed to ensure a seamless and effective deployment.
Integration Approach
- Data Syncing: The first step in integration involves syncing data between the OTT platform and the recommendation system. This includes user profiles, viewing history, and content metadata. APIs can be used to facilitate real-time data exchange, ensuring that the recommendation engine has the most up-to-date information.
- Content Categorization: The recommendation system needs to understand the content categories used by the OTT platform. Mapping the platform’s content taxonomy to the labels and categories used by the recommendation system is crucial for accurate suggestions.
- User Engagement Tracking: The recommendation engine should integrate with the platform’s tracking mechanisms to monitor user interactions, such as views, likes, and ratings. This data is essential for refining recommendations and improving the algorithm over time.
- API Integration: Seamless API integration is necessary to ensure that recommendations can be fetched and displayed in real-time as users navigate the OTT platform. This requires optimizing the API calls to minimize latency and ensure a smooth user experience.
Potential Challenges and Solutions
- Data Privacy and Compliance
- Challenge: Handling sensitive user data, such as viewing history and preferences, raises concerns about privacy and data protection, especially with regulations like GDPR and CCPA.
- Solution: Implement strong encryption, data anonymization, and comply with data protection regulations. Ensure that users have clear options for managing their data privacy settings.
- Scalability
- Challenge: OTT platforms often have millions of users and large volumes of content. The recommendation system must scale to handle this load while providing real-time recommendations.
- Solution: Use distributed computing and scalable cloud infrastructure like AWS or GCP. Implement caching strategies and batch processing to optimize performance under heavy loads.
- Content Diversity
- Challenge: OTT platforms offer a wide range of content types (movies, series, documentaries, etc.), which can make it difficult to create accurate and meaningful recommendations across all categories.
- Solution: Develop a multi-layered recommendation approach that considers different content types separately. Implement hybrid recommendation techniques that combine collaborative filtering, content-based filtering, and contextual suggestions.
- Latency and Performance
- Challenge: Real-time recommendations need to be delivered without noticeable delays, as users expect quick and responsive interfaces.
- Solution: Optimize the recommendation algorithms and API response times. Use edge computing and CDNs (Content Delivery Networks) to reduce latency by processing data closer to the user’s location.
- Integration Complexity
- Challenge: Integrating the recommendation system with an OTT platform’s existing architecture and technologies can be complex, especially if the platform is built on legacy systems.
- Solution: Use microservices architecture to decouple the recommendation system from the core platform. This allows for easier integration, updates, and scalability without disrupting the existing system.
By addressing these challenges with thoughtful solutions, OTT platforms can leverage the recommendation system to provide highly personalized and engaging content experiences, driving user satisfaction and retention.
Future Enhancements

As the recommendation system continues to evolve, several enhancements can be implemented to improve its accuracy, responsiveness, and overall utility. Here are some potential future improvements:
1. Real-Time Data Processing
- Enhancement: Integrate real-time data processing capabilities to provide instant recommendations based on the most recent user interactions. For example, if a user watches a movie or rates a show, the recommendation engine should immediately adjust its suggestions to reflect these actions.
- Implementation: Use technologies like Apache Kafka or AWS Kinesis to stream data in real-time, and integrate with Spark Streaming or Flink for processing. This ensures that the recommendation system can react to user behavior instantaneously, enhancing personalization and engagement.
2. Machine Learning Models
- Enhancement: Incorporate advanced machine learning models to improve the accuracy of recommendations. While traditional collaborative filtering and content-based filtering are effective, machine learning can provide deeper insights by understanding complex user behaviors and preferences.
- Implementation: Deploy models like matrix factorization, neural collaborative filtering, or deep learning-based recommender systems. Use frameworks like TensorFlow, PyTorch, or Scikit-learn to train and deploy these models, continuously improving them with new data.
3. Multi-Modal Recommendations
- Enhancement: Expand the system to recommend other types of content beyond movies and TV shows, such as music, books, or even products. This would allow the system to become a comprehensive recommendation engine across various domains.
- Implementation: Build a flexible architecture that supports different types of content and integrates with various content providers. Develop recommendation algorithms that can handle different data types, such as text, audio, and images, to provide relevant suggestions across multiple content formats.
4. Context-Aware Recommendations
- Enhancement: Introduce context-aware recommendations that consider factors like the time of day, user location, device type, or even current events. This can significantly enhance the relevance of recommendations by aligning them with the user’s current context.
- Implementation: Use contextual data collected from user interactions and external sources (e.g., weather, local events). Combine this data with traditional user preference data to deliver more personalized and timely recommendations.
5. Enhanced User Personalization
- Enhancement: Improve personalization by allowing users to have more control over their recommendations. This could include options to adjust the recommendation algorithm based on their current mood, interests, or specific preferences.
- Implementation: Develop user interfaces that allow for feedback and customization, such as sliders to adjust recommendation focus (e.g., more drama, less action). Implement user preference learning models that adapt over time based on explicit user feedback and interaction data.
Conclusion
In this blog, we’ve outlined the architecture of a movie recommendation system using AWS services. Starting with Amazon RDS for secure data storage, we utilized AWS DMS to keep the system updated by capturing changes and storing the latest data in Amazon S3. This ensures that our recommendation engine always works with up-to-date information.
AWS Glue played a key role in transforming this raw data into a format optimized for recommendations. By leveraging Glue’s ETL capabilities, we prepared the data for real-time processing in the Gorse recommendation engine deployed on Amazon EC2. The EC2 instance, configured for optimal performance, generates personalized movie recommendations, enhancing the user experience.
By combining these AWS services, we’ve created a scalable, efficient, and secure movie recommendation system. This architecture not only meets current needs but also provides a strong foundation for future enhancements. Whether you’re starting fresh or improving an existing system, the approach outlined here offers a reliable path to success.
Further Reading
- Skyrocket Sales: The Ultimate Guide to Recommendation Engine
- Transforming Education: How GenAI Video Search Drove Ed Tech Growth
- Why companies turning to a Fractional CTO for growth?
- How to make your OTT users search experience lightning fast?
- How GenAI Boosted OTT Company Growth to New Heights?
Follow Us
Madgical@LinkedIn
Madgical@Youtube
Disclaimer
*The views are of the author and not necessarily endorsed by Madgical Techdom.