AI Chatbot: How to Overcome Architectural Challenges
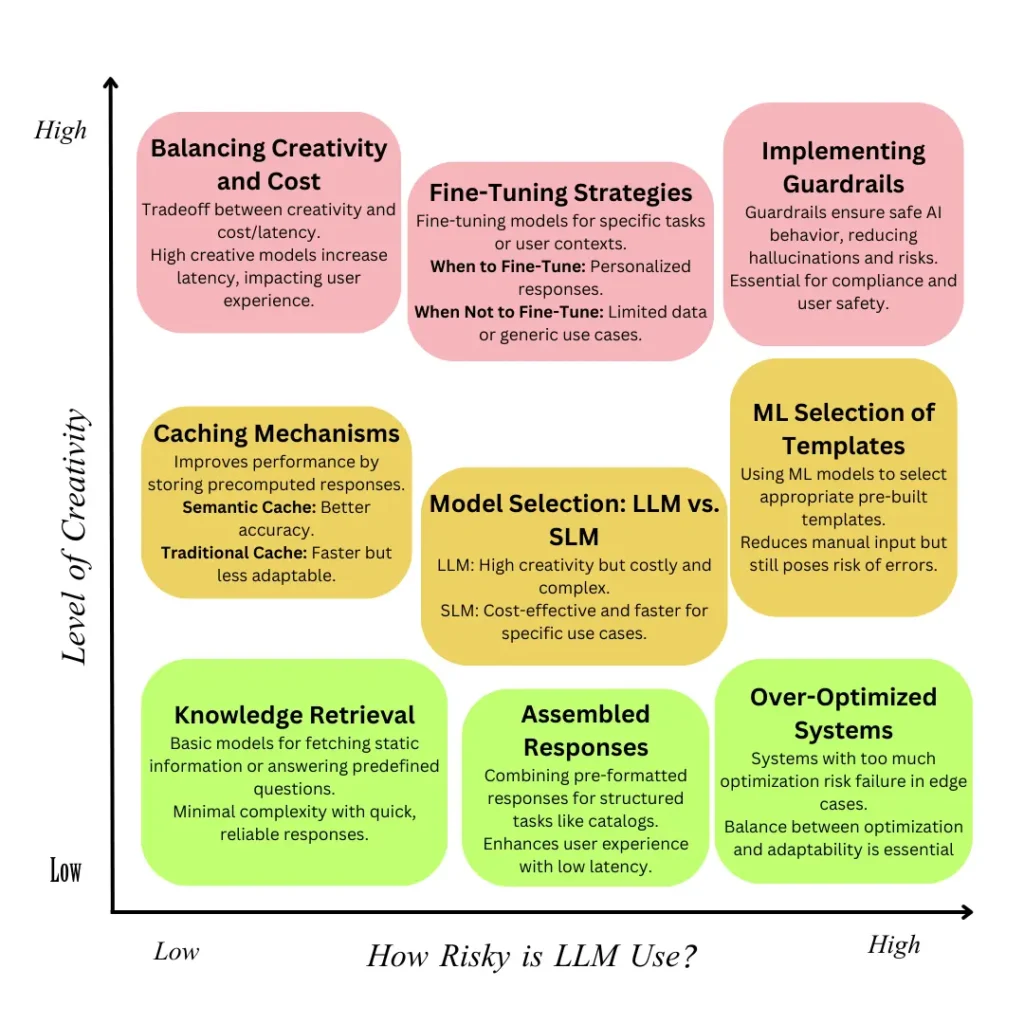
The foundation of a successful AI chatbot lies in its architecture. It is the structural blueprint that dictates how it functions, interacts, and evolves. Architectural decisions in AI chatbot design influence every aspect of its performance. These decisions affect the quality of user interactions, scalability, and cost-efficiency. They require a thoughtful balance of priorities. This balance ensures the chatbot meets its intended purpose. It also provides a seamless user experience.
Central to these architectural choices are the tradeoffs between creativity, cost, performance, and user experience. For instance, prioritizing cutting-edge natural language processing (NLP) capabilities might elevate creativity and conversational depth but could increase development costs and response times. On the other hand, optimizing for speed and cost-effectiveness might limit the bot’s ability to engage users in rich, nuanced conversations.
Understanding and navigating these tradeoffs is crucial for creating AI chatbots that are not only functional but also effective in delivering value to users. This section explores these tradeoffs and the pivotal role they play in shaping the chatbot’s design and ultimate success.
Balancing Creativity and Cost in AI Chatbot Design

Designing AI chatbots involves balancing the desire for creative responses with the practical constraints of cost and latency. Creativity, powered by advanced models like GPT, can elevate user interactions with engaging, context-aware responses. However, these models are resource-intensive, requiring high computational power and storage. This increases costs significantly, especially when serving a large user base. Additionally, the complexity of generating creative responses often results in longer response times, which can disrupt user experience.
The Cost of Creativity
Sophisticated models excel at nuanced conversations but demand expensive cloud infrastructure and processing power. Real-time applications further strain resources, making every additional second of processing costly. As usage scales, the costs of maintaining such systems grow exponentially. For many businesses, this becomes unsustainable unless justified by exceptional value in user satisfaction or revenue.
Latency and Its Impact
Latency—delays in generating responses—can critically affect the usability of a chatbot. In customer support scenarios, users often prioritize speed over creativity. A delayed reply, no matter how well-crafted, can frustrate users, especially during urgent queries. Similarly, in e-commerce, delays in providing product recommendations may lead to user disengagement and lost sales. In healthcare applications, where timely assistance is paramount, latency can undermine user trust and compromise effectiveness.
Finding the Balance
To balance creativity, cost, and latency, chatbot developers must align the architecture with the chatbot’s purpose. For high-priority applications, lightweight models can handle routine tasks quickly, while creative models are reserved for specific use cases requiring depth. Techniques like caching frequent responses, batch processing, or employing scalable infrastructure also help mitigate costs and reduce latency.
This balance ensures that chatbots remain engaging, efficient, and aligned with user expectations without incurring unsustainable costs or delays.
Assessing Creativity and Risk in AI Chatbot Design

Incorporating creativity into AI chatbots enhances user engagement and provides dynamic, personalized interactions. However, creativity comes with its own set of risks, especially in sensitive contexts where accurate and safe communication is critical. Highly creative responses generated by advanced models can sometimes deviate into unintended areas, posing risks such as misinformation, offensive content, or even compromising user safety. Balancing creativity and risk is essential to ensure chatbots remain reliable and trustworthy.
Potential Risks of Creative Responses
- Misinformation: Advanced AI models may generate plausible but factually incorrect information. For example, a chatbot answering medical queries might provide inaccurate health advice, leading to user harm. Similarly, in educational contexts, a creative but incorrect response can misguide learners.
- Offensive or Harmful Content: Highly creative chatbots may inadvertently generate responses that are culturally insensitive or inappropriate, especially when they are not adequately trained on diverse, high-quality datasets.
- User Safety: In contexts like mental health or crisis intervention, overly creative responses, therefore, may misinterpret the user’s intent or fail to provide the appropriate support. As a result, this could potentially worsen their situation.
Strategies to Mitigate Risks
- Context-Aware Constraints: Use guardrails to limit creativity in sensitive domains. For instance, predefined templates or controlled language models can ensure accuracy and appropriateness where factual correctness is critical.
- Human Oversight: Implement a fallback system that escalates complex or risky interactions to human agents for review and response.
- Reinforcement Learning: Train chatbots to prioritize safe and factual responses using reinforcement learning with human feedback (RLHF). This helps models align with ethical and safety standards.
- Regular Audits and Testing: Continuously monitor chatbot outputs to identify and rectify biases or inaccuracies. Frequent updates to the training data improve reliability over time.
By thoughtfully addressing these risks, developers can harness the benefits of creativity while maintaining user trust and safety.
AI Chatbot Model Selection

LLM vs. SLM
When designing AI chatbots, one of the most critical decisions is choosing between a Large Language Model (LLM) and a Smaller Language Model (SLM). Each type has distinct advantages and tradeoffs in terms of performance, cost, and applicability. Understanding these differences helps developers choose the right model based on the specific requirements of their chatbot.
Large Language Models (LLMs)
LLMs, like GPT-3 or GPT-4, are powerful models trained on vast amounts of data, enabling them to generate highly nuanced, context-aware responses. They excel in generating creative and complex conversations, handling a wide range of topics with ease. However, their size and computational complexity come with a cost—LLMs are resource-intensive and require significant processing power, which can lead to higher operational costs and latency. Despite these challenges, LLMs are ideal for use cases where sophisticated, varied, and highly personalized interactions are essential, such as virtual assistants, content generation, or dynamic customer support.
Smaller Language Models (SLMs)
SLMs are more lightweight models that are trained on smaller datasets and optimized for specific tasks. While they may lack the general conversational versatility and creativity of LLMs, SLMs are fast, cost-efficient, and easier to deploy in resource-constrained environments. They perform well in narrow use cases such as FAQ bots, task-specific assistants, or environments with limited computational resources. SLMs can provide quick, accurate responses, making them a solid choice for applications where simplicity and speed outweigh the need for highly dynamic conversations.
How to Choose Models?
When selecting between an LLM and an SLM, consider the following factors:
- Use Case: If your chatbot needs to engage in complex, open-ended conversations or generate creative content, an LLM is a better fit. For focused tasks like answering standard questions or providing straightforward support, an SLM may suffice.
- Available Data: LLMs benefit from vast datasets, while SLMs are better suited for specialized domains with limited data. If you’re working with a specific niche (e.g., legal or medical domains), an SLM can be trained with relevant, high-quality data to achieve optimal performance.
- User Expectations: If users expect dynamic, personalized interactions, LLMs will better meet these expectations. However, if they prioritize speed and reliability over creativity, an SLM will provide a more efficient solution.
- Deployment Environment: LLMs require substantial computational resources for real-time interactions, making them ideal for cloud-based environments with high scalability. SLMs are better suited for edge deployments or environments with limited bandwidth or processing power.
Ultimately, the choice between LLM and SLM depends on your chatbot’s specific needs, budget, and technical constraints. A well-considered decision ensures that the model aligns with both user expectations and system requirements.
AI Chatbot Fine-Tuning Strategies

When to Use Fine-Tuning
Fine-tuning is the process of adapting a pre-trained model to a specific task or domain by further training on a smaller, specialized dataset. This approach is especially beneficial in the following scenarios:
1. Context-Aware Responses
Fine-tuning helps make a model more context-aware by training it on specific data relevant to your use case. For example, a healthcare chatbot fine-tuned on medical data will better understand domain-specific terminology, ensuring more accurate and relevant responses.
2. Reducing Hallucinations
Pre-trained models can sometimes generate incorrect or misleading information. However, fine-tuning with domain-specific data helps reduce these ‘hallucinations’ by guiding the model to provide factually accurate, contextually appropriate responses.
3. Aligning with Brand Voice
Fine-tuning can help a chatbot adopt a specific tone and style that aligns with your brand. Whether you want a formal, professional tone or a friendly, conversational one, fine-tuning ensures the chatbot communicates consistently with your audience.
In summary, fine-tuning improves a model’s performance by making it more context-aware, reducing the risk of generating false information, and tailoring its responses to match your brand’s voice.
When Not to Fine-Tune
While fine-tuning can significantly enhance a model’s performance in specific scenarios, there are situations where fine-tuning may not be the best option. Here are some cases where fine-tuning may not yield substantial benefits:
1. Limited Data Availability
Fine-tuning requires a sufficient amount of high-quality, domain-specific data. If you have a small or low-quality dataset, fine-tuning may not improve the model’s performance and can even lead to overfitting, where the model becomes too tailored to the training data and loses its generalization ability. In such cases, starting with a pre-trained model without fine-tuning might be more effective, or using transfer learning techniques on larger datasets could yield better results.
2. General-Purpose Tasks
If your chatbot performs general tasks or responds to a wide range of inquiries without requiring domain-specific knowledge or personality traits, fine-tuning may not provide substantial improvements. Pre-trained models, like GPT, are already highly capable for general-purpose use and may not need further fine-tuning. In these scenarios, the effort and computational cost of fine-tuning may outweigh the benefits.
3. Resource Constraints
Fine-tuning large models requires significant computational resources and time. However, if you’re working in a resource-constrained environment or need to deploy quickly, fine-tuning might not be a viable option. In such cases, it may be better to use a smaller, lightweight model that performs adequately without the need for fine-tuning.
4. Data Changes Frequently
If the data you are working with changes frequently, fine-tuning may not be sustainable in the long term. Fine-tuned models can quickly become outdated as the data evolves, requiring regular retraining and fine-tuning efforts to stay relevant. In such cases, it might be more practical to use models that are more flexible and capable of adapting to new data without needing constant fine-tuning.
In these situations, using a pre-trained model or exploring other techniques like few-shot learning or rule-based approaches might be more efficient and cost-effective. Fine-tuning should be reserved for situations where domain-specific data and performance improvements justify the additional effort and resources.
AI Chatbot Caching Mechanisms for Improved Performance

When to Cache, When Not To
Caching is a key technique to enhance performance in AI chatbots by storing frequently accessed data or responses, reducing the need for redundant processing. However, caching should be implemented thoughtfully to avoid unnecessary complexity and resource consumption.
When to Cache:
- Frequently Accessed Data: Caching works well for static, commonly requested data, such as office hours or FAQ responses. Storing these in the cache speeds up response time and improves user experience.
- Expensive Computational Tasks: For resource-intensive processes (like complex calculations or API calls), caching prevents repeated computation. This reduces latency and saves computational power.
- Rate-Limiting and Load Management: If external APIs have rate limits, caching helps by minimizing calls to those services, managing load more efficiently and preventing service disruptions.
When Not to Cache:
- Dynamic or Real-Time Data: Caching is less useful for data that constantly changes, such as live news or stock prices, as outdated information could harm the user experience.
- Highly Personalized Responses: Personalized, context-sensitive data (like user-specific recommendations) should not be cached, as cached responses could be irrelevant or inaccurate.
- Memory and Storage Constraints: In resource-limited environments, excessive caching may consume too much memory and storage, counteracting its performance benefits.
In conclusion, cache when performance boosts are clear, but avoid it for real-time, dynamic, or personalized data.
Semantic Cache vs. Traditional Cache
Caching mechanisms are used to improve the performance of systems by storing data temporarily. However, not all caches are the same. Semantic caching and traditional caching are two approaches with distinct purposes and use cases. Understanding the differences between them can help determine which is best suited for your chatbot’s needs.
Traditional Cache
Traditional caching involves storing data or responses based on exact matches of the requested information. This method works by saving entire responses or raw data for frequently accessed requests. For instance, if a user asks for the weather forecast and the chatbot retrieves this from an external API, traditional caching would store the exact weather data, and future requests for the same location would be served directly from the cache.
Use Cases:
- Static Data: Ideal for static data that doesn’t change often, like office hours or general FAQ responses.
- Frequent Requests: Useful for frequently requested information to minimize retrieval time and reduce load on backend systems.
Semantic Cache
Semantic caching, on the other hand, focuses on storing the meaning or context of the requested information rather than the exact data itself. It stores query results in a way that allows partial matches or contextually similar data to be reused. For example, if a user asks about a specific product’s features and another user asks about a similar product, the semantic cache can serve a relevant, modified response, saving computation time by using stored knowledge about the similarities between the two products.
Use Cases:
- Context-Aware Data: Effective for use cases where the chatbot needs to understand and respond to variations in user queries or requests with similar underlying meanings (e.g., synonyms or paraphrases).
- Dynamic Queries: Ideal for queries with flexible or partially dynamic data, like product recommendations or user-specific information.
Key Differences
- Granularity: Traditional caching stores complete responses based on exact requests, while semantic caching stores contextual or meaningful information that can be adapted to different queries.
- Flexibility: Semantic caching is more flexible, allowing for reuse of stored data in a variety of contexts, whereas traditional caching is limited to exact data matches.
- Use Case Fit: Traditional caching is better suited for static, repeated data, while semantic caching excels in dynamic environments where context and meaning matter, such as personalized user interactions.
In conclusion, while traditional caching is efficient for repeated exact matches of data, semantic caching offers more flexibility and intelligence by storing the underlying context and meaning, making it ideal for dynamic, context-aware applications like AI chatbots.
Implementing Guardrails
When to Use Guardrails
Guardrails are safety measures implemented to guide AI behavior, ensuring that it operates within acceptable boundaries. They help prevent AI from engaging in harmful, unethical, or non-compliant behavior, ensuring safe interactions and protecting both users and organizations.
Importance of Guardrails
Guardrails are essential for controlling AI’s actions in scenarios where responses could be unpredictable or inappropriate. They ensure that the AI adheres to organizational standards, legal requirements, and ethical considerations, providing a safeguard against misinformation, security risks, or biased responses.
Key Scenarios for Guardrails
- Sensitive Topics: For chatbots in fields like mental health or medical advice, guardrails ensure that the AI provides accurate, non-harmful information and avoids offering diagnoses or dangerous advice.
- User Safety: Guardrails protect against the AI asking for sensitive data like passwords or financial information, preventing security risks and ensuring user safety.
- Compliance with Regulations: In sectors such as healthcare or finance, guardrails enforce adherence to legal standards (e.g., GDPR, HIPAA), ensuring that the AI doesn’t violate user privacy or provide non-compliant recommendations.
- Ethical Boundaries: Guardrails also prevent AI from generating biased, discriminatory, or offensive content, ensuring fairness and ethical behavior, especially in areas like recruitment or public services.
In summary, guardrails are essential for maintaining AI safety, legality, and ethics, particularly when dealing with sensitive data or topics.
Striking a Balance: Engineering vs. Over-Engineering
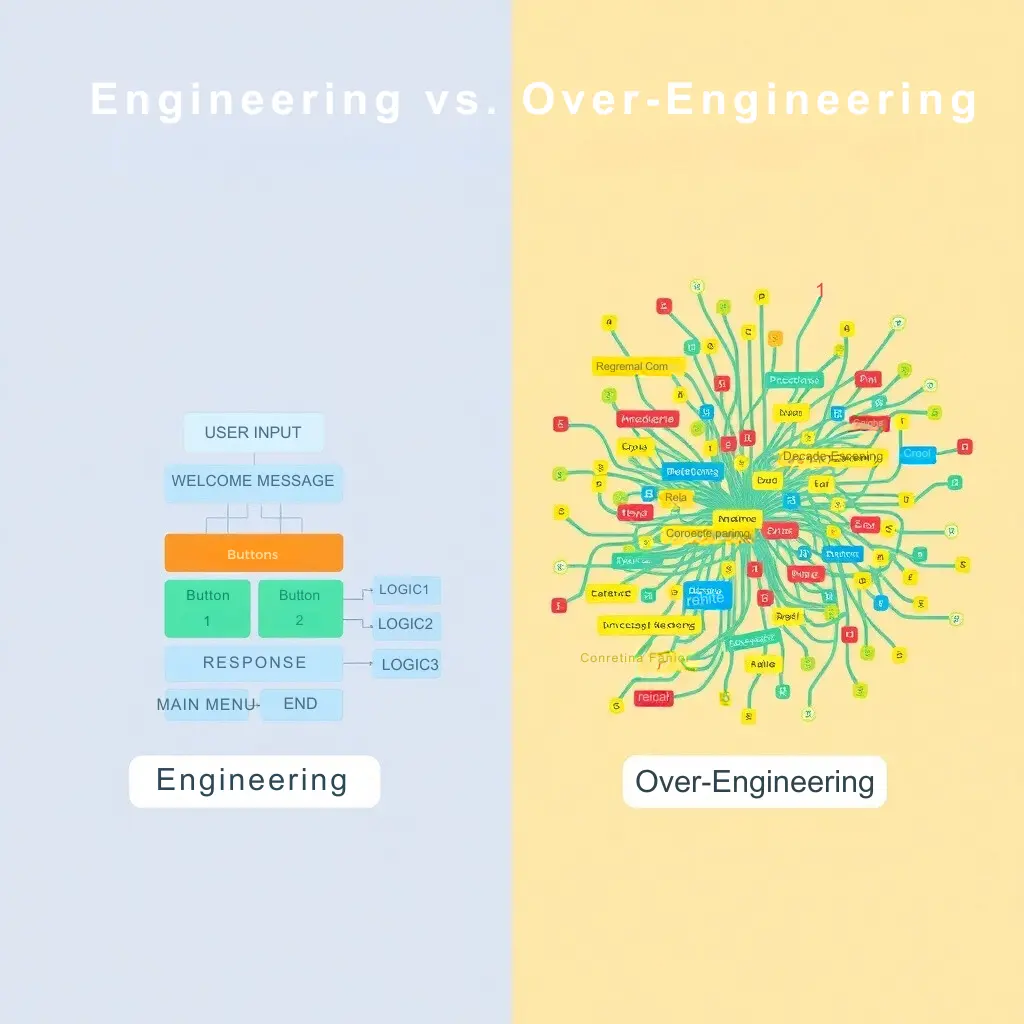
Over-engineering refers to the practice of adding unnecessary complexity to a solution, often in an attempt to anticipate future problems or create features that are not essential. While it might seem like a proactive approach, over-engineering can introduce significant risks, particularly in AI chatbot architecture and system design.
Risks of Over-Engineering
- Increased Complexity: Over-engineering can result in overly complex systems that are difficult to understand, maintain, and debug. This can lead to a higher chance of introducing bugs or errors, which ultimately reduces the reliability of the system.
- Higher Costs: Additional complexity often translates into increased development and maintenance costs. Time and resources spent on unnecessary features could have been better invested in improving core functionality or user experience.
- Slower Time to Market: Over-engineered solutions tend to have longer development cycles, as engineers focus on building unnecessary components or anticipating edge cases that may never arise. This delays the deployment of the product, potentially giving competitors a market advantage.
- Reduced Flexibility: Over-engineered systems are often rigid, making it harder to adapt to changes or scale the system as new requirements emerge. This limits long-term adaptability and can hinder innovation.
Importance of Simplicity and Maintainability
Striking a balance between functionality and simplicity is essential for long-term success. A simple, well-structured architecture is easier to maintain, modify, and scale. Focusing on the core features that provide real value ensures a quicker time to market and a more cost-effective solution. Additionally, simplicity fosters clear communication and collaboration among teams, allowing for faster problem-solving and troubleshooting.
In conclusion, while it’s tempting to anticipate every possible scenario, over-engineering often leads to more problems than it solves. A focus on simplicity, maintainability, and core functionalities ensures that systems remain adaptable, cost-effective, and scalable in the long term.
AI Chatbot Metrics for Success and Performance Evaluation
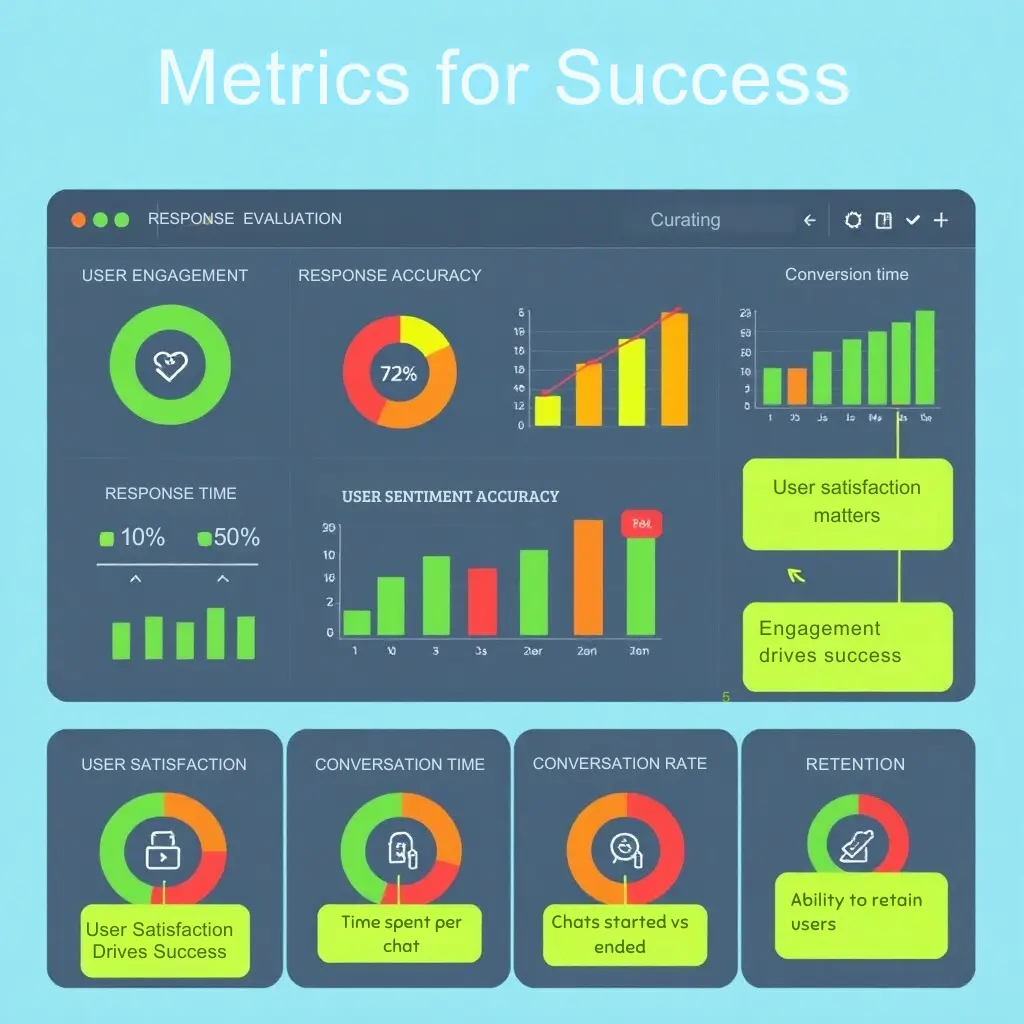
Evaluating the effectiveness of a chatbot requires a clear understanding of key performance indicators (KPIs) that reflect its performance, user satisfaction, and overall success in meeting objectives. The right metrics provide valuable insights into how well the chatbot serves users, highlights areas for improvement, and helps track its impact on business goals.
Key Performance Indicators (KPIs) for Evaluating Chatbot Effectiveness
- Response Accuracy: This metric measures how often the chatbot provides correct and relevant responses to user queries. A high response accuracy rate indicates that the chatbot is well-trained and effectively addressing user needs.
- User Engagement: Metrics like conversation length, the number of interactions, and the frequency of return users are important to assess how engaging the chatbot is. High engagement suggests users find value in the bot’s interactions.
- User Satisfaction (CSAT): Collecting user feedback through post-interaction surveys or ratings allows you to gauge user satisfaction. A high CSAT score reflects positive user experiences and successful chatbot performance.
- Conversion Rate: For chatbots in sales or support, tracking the conversion rate—whether users complete a desired action (e.g., purchasing a product, signing up for a newsletter)—helps evaluate the chatbot’s impact on business goals.
- Response Time: The speed at which the chatbot responds to user queries plays a key role in user experience. Lower response times generally correlate with higher user satisfaction and better overall performance.
- Fall-Back Rate: This metric tracks the number of times the chatbot fails to provide a satisfactory answer and escalates the query to a human agent. A high fall-back rate may indicate areas where the chatbot’s knowledge base needs expansion or improvement.
Importance of User Feedback and Continuous Improvement
While KPIs provide quantitative data, user feedback offers valuable qualitative insights that highlight areas for improvement. Collecting feedback through surveys, ratings, or direct input helps identify chatbot weaknesses and refine its functionality. Combining this with KPI data allows teams to enhance response accuracy and adapt to user needs.
Continuous improvement is essential for long-term chatbot success. Regular updates to the knowledge base, refining natural language processing, and analyzing performance ensure the bot remains effective and aligned with business goals.
In summary, tracking KPIs and leveraging user feedback are key to enhancing chatbot performance, ensuring a better user experience, and achieving sustained success.
AI Chatbot Frameworks, Models, and Tools for Effective Design

Choosing the right frameworks and tools is key to building effective AI chatbots that perform well and provide a seamless user experience.
Popular Frameworks
- Rasa: An open-source, customizable framework for building complex, context-aware chatbots with advanced NLU and dialogue management. Ideal for businesses seeking full control and self-hosting.
- Dialogflow: A cloud-based platform by Google that offers easy setup, powerful NLP, and integration with Google services. Best for developers needing quick deployment with pre-built templates.
- Microsoft Bot Framework: A comprehensive suite for enterprises using Microsoft’s cloud services, with integration to cognitive tools like speech recognition and language understanding.
Monitoring Tools for Performance and Engagement
- Bot Analytics Tools: Platforms like BotAnalytics and Dashbot track user interactions, drop-offs, and sentiment to optimize performance.
- New Relic: A tool for monitoring server-side performance, response times, and system health to ensure smooth chatbot operation.
- Google Analytics: Useful for monitoring chatbot interactions on websites, tracking user behavior and engagement metrics.
Guardrails and Monitoring Solutions
- Guardrails: Tools like Hugging Face’s AI Safety Toolkit help ensure chatbots meet safety and compliance standards.
- Sentiment Analysis: Tools like VaderSentiment or IBM Watson monitor user sentiment, enabling the chatbot to adjust responses for improved interactions.
- User Feedback: Collecting feedback through surveys or rating buttons helps continuously improve chatbot performance.
In conclusion, using the right frameworks and monitoring tools ensures chatbots are efficient, engaging, and safe, with continuous improvement based on user data.
Conclusion
Designing AI chatbots involves a delicate balancing act between various architectural tradeoffs. Throughout this post, we’ve discussed key considerations such as creativity vs. cost, performance vs. user experience, and the selection of appropriate models and frameworks. Whether it’s choosing between Large Language Models (LLMs) and Smaller Language Models (SLMs), deciding when to implement fine-tuning, or understanding the importance of caching and guardrails, each decision impacts the chatbot’s effectiveness and user satisfaction.
As chatbot developers and businesses, it’s crucial to make thoughtful design choices that align with your goals, available resources, and user needs. Striking the right balance can lead to a more efficient, responsive, and safe chatbot, while over-engineering or neglecting certain aspects can lead to performance issues or suboptimal user experiences.
We encourage you to reflect on the architectural tradeoffs in your own chatbot projects. Carefully assess the risks, benefits, and constraints of each choice to ensure you’re building an AI chatbot that meets both technical requirements and user expectations. Thoughtful planning and decision-making are key to creating chatbots that deliver meaningful, reliable, and engaging experiences for users.
Further Reading
- Skyrocket Sales: The Ultimate Guide to Recommendation Engine
- AI Chatbots: Discover how to reap its benefits
- Why companies turning to a Fractional CTO for growth?
- How to make your OTT users search experience lightning fast?
- How GenAI Boosted OTT Company Growth to New Heights?
Follow Us
Madgical@LinkedIn
Madgical@Youtube
Disclaimer
*The views are of the author and not necessarily endorsed by Madgical Tec