How to make your OTT users search experience lightning fast?

Introduction
Imagine you’re managing an OTT platform that entertains millions with a huge library of movies and TV shows. As more people subscribed and our content catalog expanded, keeping the OTT users search experience smooth and seamless became a real challenge. The big question we faced was: How do we help users easily find what they’re looking for in such a vast selection?
Traditional search methods just weren’t cutting it anymore. Today’s users want to search for content by specific criteria—like actors, directors, or even plot details. To meet this demand, we needed a much more advanced search solution, one that could handle massive amounts of real-time data and manage complex queries without a hitch.
So, we set out to integrate a cutting-edge search engine into our platform’s architecture. But this wasn’t an easy task. The biggest challenge was moving large volumes of data from our primary database to the new search engine without slowing down the platform’s performance and ensuring the data remained up-to-date.
In the following sections, we’ll dive into the technical challenges we encountered and explore the different solutions we considered to overcome them.
Challenges

Let’s break down the challenges and explore the complexities of enhancing the user experience on an OTT platform.
1. Evolving User Expectations
As the subscriber base grew and the content catalog expanded, we quickly realized that our traditional search methods weren’t cutting it anymore. Today’s users are incredibly savvy—they want to search not just by the title but by very specific criteria like actors, directors, and even plot details. Meeting these elevated expectations became a critical challenge because, frankly, anything less could frustrate users, pushing them to abandon the platform for one that offers a more sophisticated search experience.
Take, for example, one of the OTT platforms. Users can search by genre, cast members, or even specific scenes—this sets a very high standard. When users are accustomed to this level of detail and precision, falling short of it risks user dissatisfaction and potential churn. Therefore, ensuring that our platform could meet and exceed these expectations was non-negotiable.
2. Managing Real-Time Data and Complex Queries
To offer the advanced search functionality our users were demanding, we had to ensure that our search engine could handle vast amounts of real-time data and process complex queries efficiently. This was no small feat—the challenge lay in integrating a solution that could do all this without overwhelming our existing infrastructure.
Think of it like a mini Google Search—processing millions of queries per second and delivering lightning-fast results. Users expect this level of performance from an OTT platform, and anything less would be noticeable and detrimental. Achieving this meant carefully considering both our technology stack and our architectural choices to ensure we could deliver that level of service.
3. Data Migration and Performance Impact
Perhaps the most daunting challenge was migrating vast volumes of data from our primary database to the new search engine. This wasn’t just about moving data—it was about doing so in a way that didn’t slow down the platform or cause any downtime. Plus, we had to keep the data synchronized across multiple systems, ensuring everything was up-to-date.
Imagine the challenges e-commerce platforms face when they update product information across multiple databases—any delay or downtime could cost them sales. Similarly, on an OTT platform, users expect instant access to content. A delay could mean the difference between a satisfied user and one who opts to switch to a competitor. The stakes were just as high for us, and ensuring a seamless migration was crucial.
Each of these challenges was significant, requiring a thoughtful and strategic approach. But overcoming them was key to not just meeting user expectations but exceeding them, all while maintaining the platform’s high performance and reliability.
The solution we offered

To address the challenge of meeting evolving user expectations and improving the overall experience, we knew we had to overhaul our search capabilities. This wasn’t just about upgrading the search bar—it was about transforming the entire user journey from content discovery to engagement.
The Technical Solution: A Real-Time Data Synchronization Pipeline
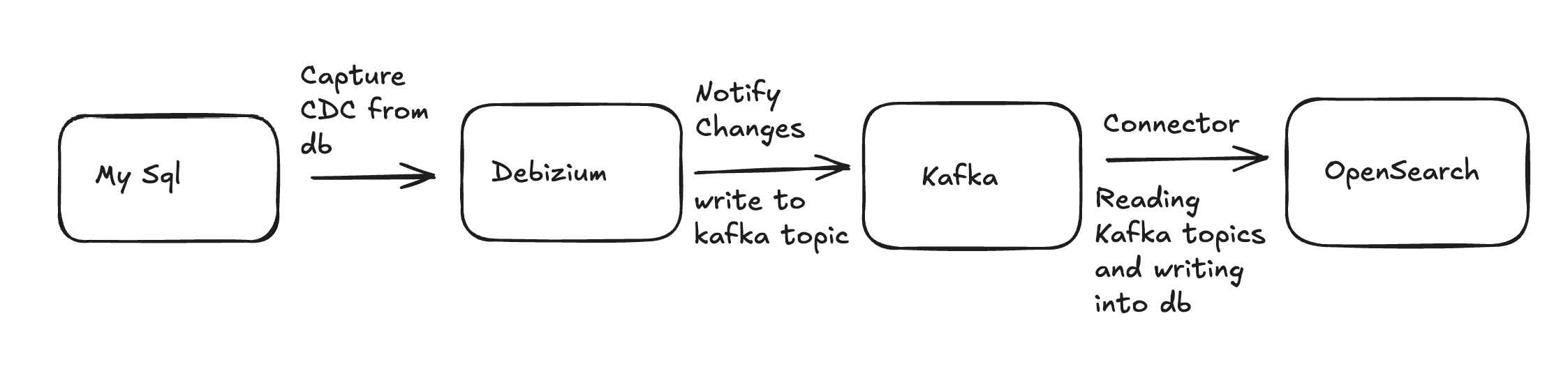
We started by developing a real-time data synchronization pipeline between our MySQL database and OpenSearch. Now, that might sound like a lot of technical jargon, but let me break it down in simpler terms.
Imagine your MySQL database as a massive warehouse storing all your content data—every show, every movie, every piece of metadata. On the other hand, OpenSearch is like a supercharged search engine specifically designed to handle complex queries and deliver fast, relevant results. The challenge was to keep these two systems in sync so that whenever new content was added or updated in the MySQL database, it would instantly reflect in OpenSearch without any delays.
To make this happen, we leveraged a few key technologies:
- Debezium: This tool acts like a monitor for the MySQL database. It watches for any changes—like new content being added or existing data being updated—and immediately captures these changes.
- Kafka: Once Debezium captures the changes, it sends this data to Kafka, which is like a high-speed messaging system. Kafka ensures that these changes are transmitted quickly and reliably, so there’s no lag between when something is updated in the database and when it shows up in the search engine.
- OpenSearch: Finally, OpenSearch takes the data it receives from Kafka and updates its index, ensuring that users can find the most up-to-date content with their searches.
By establishing this real-time data synchronization pipeline, we didn’t just improve search speed and accuracy—we fundamentally changed the way users interact with our platform. It transformed our OTT platform from a static content repository into a dynamic, user-focused discovery tool.
This initiative allowed users to find exactly what they were looking for, even if they only had a vague idea, like remembering an actor or a particular scene. The result? Increased user satisfaction, longer engagement times, and ultimately, more loyalty to our platform.
And from a business perspective, this was a game-changer. When users can easily discover and engage with content, it drives not just user retention but also subscription growth. Essentially, this technical solution helped align our platform more closely with user expectations, fueling both our audience’s satisfaction and our business’s success.
Github : https://github.com/madgicaltechdom/kafka-nodejs.git
Benefits
Now that we’ve implemented a real-time data synchronization pipeline between our MySQL database and OpenSearch, the benefits have been game-changing.
1. Advanced Search Functionality
By integrating OpenSearch, we unlocked a highly advanced and flexible search engine for our platform. Now, users can search for content with incredible precision—whether they’re looking for specific titles, genres, actors, directors, or even particular plot elements. For instance, if a user wants to find movies starring their favorite actor or explore films directed by a specific filmmaker, it’s all just a search away.
2. Enhanced User Experience
The quality of our search results has skyrocketed, leading to a noticeable improvement in user satisfaction. Gone are the days of users struggling to find the content they love. With more relevant and accurate search results, frustrations have decreased, and users are more engaged than ever.
3. Informed Decision-Making
One of the big wins from the real-time data pipeline is the insights we now get into user behavior. We can track what people are searching for in real-time, helping us fine-tune search algorithms and improve content recommendations. This kind of data allows us to constantly evolve, offering a smarter, more personalized experience.
4. Boosted Content Discovery
Perhaps the best outcome has been how easily users can now discover new content. The advanced search features make it easy for them to stumble upon shows or movies they might not have found otherwise, increasing both engagement and overall content consumption. In the end, it’s a win-win for both the users and the platform.
Alternative Solutions for ETL from MySQL to OpenSearch on AWS
When integrating MySQL data with OpenSearch on AWS, several ETL (Extract, Transform, Load) solutions are available. While Debezium, Kafka, and OpenSearch are popular for real-time and robust ETL processes, the choice of alternatives depends on specific business needs, real-time or batch processing, scalability, and management overhead.
1. AWS-Managed Services:
AWS Glue (Managed ETL Service):
AWS Glue is a serverless ETL service designed to automate and orchestrate data flows. It can pull data from MySQL, transform it, and load it into OpenSearch. While Glue is built for batch processing, it can be combined with other services for near real-time data processing.
- Pros:
- Serverless architecture; no infrastructure management.
- Seamless integration with other AWS services (S3, Athena, OpenSearch).
- Scalable for large datasets.
- Simplifies ETL through built-in transformations.
- Cons:
- Primarily batch-oriented; not ideal for real-time data processing without additional services.
- Higher costs for extensive data processing over time.
- Can have a steeper learning curve for complex transformations.
AWS DMS (Database Migration Service):
AWS DMS is primarily a database migration tool, but it can also handle continuous data replication. This service allows incremental data loads from MySQL to OpenSearch. However, it may not be the best fit for large-scale real-time ETL needs.
- Pros:
- Easy setup for data replication tasks.
- Near real-time data synchronization.
- Built-in support for common migration use cases.
- Cons:
- Suboptimal for real-time, high-throughput data loads.
- Limited transformation capabilities compared to dedicated ETL tools.
- It requires fine-tuning to achieve optimal performance for continuous loads.
AWS Lambda with Kinesis Data Firehose:
This serverless solution allows real-time ETL processing using AWS Lambda functions to extract data from MySQL and Kinesis Data Firehose to deliver it to OpenSearch.
- Pros:
- Fully serverless and scalable for real-time data ingestion.
- Near real-time data loading.
- Easy to integrate and extend with additional AWS services.
- Cons:
- May require custom code within Lambda for complex transformations.
- Monitoring and debugging large-scale real-time flows can be complex.
- Potentially higher costs as the volume of events increases.
2. Open-Source Tools:
Logstash (Open-Source):
Logstash is a flexible data processing pipeline that can be used to extract data from MySQL, transform it, and load it into OpenSearch. As part of the ELK (Elasticsearch, Logstash, Kibana) stack, it provides powerful customization but requires more manual configuration and monitoring.
- Pros:
- Highly customizable and flexible for different ETL workflows.
- Wide community support and plugins for various data sources and formats.
- Well-suited for real-time log and data ingestion.
- Cons:
- Requires infrastructure management (scaling, monitoring, and maintenance).
- Can be resource-intensive for high-throughput workloads.
- More complex setup and operational overhead compared to managed services.
Apache Airflow (Open-Source Workflow Orchestration):
Apache Airflow is used for orchestrating complex ETL workflows, where data extraction, transformation, and loading tasks can be scheduled and automated. It is useful for managing larger workflows but does not handle real-time processing by itself.
- Pros:
- Ideal for orchestrating complex ETL workflows with dependencies.
- Open-source with an active community and plugin ecosystem.
- Allows flexibility in defining custom tasks and execution sequences.
- Cons:
- Not suited for real-time data ingestion out of the box.
- Requires infrastructure management (servers, scaling).
- It requires knowledge of Python and workflow orchestration.
Conclusion
In the rapidly evolving landscape of OTT platforms, providing a seamless and responsive search experience is crucial. Implementing a real-time data synchronization pipeline between MySQL and OpenSearch, powered by robust ETL workflows, is a strategic move that ensures your platform remains competitive and user-centric.
By configuring a Change Data Capture (CDC) tool like Debezium, transforming the captured data, and efficiently indexing it into OpenSearch, you can maintain an up-to-date and accurate search index that responds instantly to user queries. This approach not only enhances user satisfaction by delivering precise search results but also scales with your growing content library and user base.
Addressing the key aspects of this integration—such as data volume management, real-time updates, and performance optimization—enables you to build a search solution that is both robust and flexible. As a result, your platform can continue to deliver high-quality, personalized content discovery experiences that drive engagement and business growth.
References
- How to Achieve 60% AWS Cost Optimization with Functions and Tags
- How to Optimize QA Automation for 30% Quicker Releases
- 30% Time Savings in AI Development: The EKS CI/CD Solution
- How to Get Started with Terraform: A Step-by-Step Guide
Follow US
Disclaimer
The views are those of the author and are not necessarily endorsed by Madgical Techdom.