How to Automate AI Chatbot Testing Using Our Best Solution?

Introduction
In the bustling world of technology, where businesses strive to connect with customers seamlessly, MadgicalTechdom emerges as a beacon of innovation. At our core lies an AI-powered conversational platform, meticulously crafted to revolutionize customer engagement and support services. AI chatbots, after undergoing meticulous testing, serve as potent tools for simulating intelligent conversations with users and making a profound impact on people’s lives.
So, in our collaboration with SwiftChat, a platform used by 20 million people, we were working on developing bots for diverse purposes, including educational chatbots like Bhagwat Geeta, Ramayan, and Mahabharat. We created the bot, but during our development phase, we hit a big problem: testing these bots. Because of the great significance of these bots, ensuring their proper functionality was important.
However, testing AI chatbots was not as simple as traditional testing. One of the main issues we had was the hallucination of GenAI. Here, the hallucination of GenAI meant that our chatbot sometimes gave unexpected and unrelated answers to questions. This made it hard for the bot to stay on track and do its job properly. Other issues that we had were the rapid change in data, repeated testing, and high time consumption.
So, we looked into the challenge and searched for the solution. We found out about the “Bert” and “Glove” models that we used in our solution. Let’s delve into our experience of testing AI chatbots, discussing the hurdles we faced, how we tackled them, and the impact it has.
Top 4 challenges we faced while testing the educational bot
As discussed above, we created educational bots. So it was important for us to test these bots completely to make sure they met our expectations and generated the answers that we wanted. But it was not that easy; we faced some challenges where we had to put a lot of effort into testing the AI conversations. Let’s look into the major issues we faced:

- Manual effort in testing a large number of questions: Imagine having a set of 500–1000 questions, and you have to generate the answers to each question manually and then check if the answers are correct or not. Isn’t it a tedious task? So this was our main challenge, where we put a lot of manual effort into checking and generating the answers to every question.
- Not able to use the traditional way of automation: It was not possible for us to use the traditional way of automation. In which we match every string to check answers. Because the bot can generate the correct answer to the same question in different ways.
- It is difficult to test all user input variations. Testing AI chatbots was tough because people ask questions in many ways with different words and tones. Checking all these possibilities manually was time-consuming.
- High time consumption in repeated testing: During the development phase, the project data kept changing, due to which we had to test the bot many times with different user questions. But as we had to test it manually, it took longer than we thought it would. Usually, doing the testing by hand took about two days for each round, in which we had to both generate the answers and then verify them.
Our solution for automation testing
Now that we knew the challenges we had, we decided to automate our tests. We searched for resources to help us automate our tests based on these challenges. After some searching, we found advanced methods like BERT and GloVe models. These models utilize advanced natural language processing techniques to understand the semantic meaning and context of textual data. We are happy to share the technique that led us to reduce the testing effort. Let’s look into our solution in detail.
1. Defining Test Objectives
We started by deciding what to check in our testing. It’s important because it helps us understand what we want our bot to do. Our bot talks about things like Bhagwat Geeta, Mahabharat, Ramayana, and more. So, we wanted to make sure our bot could give the right answers when users asked questions.
2. Creating a Question Bank with a Golden Set
After deciding what we wanted to test, we thought about all the different situations. Our bot’s job is to answer questions from users. So, we made a list of all the questions users might ask. We put all these questions on a sheet with three main columns: question, expected answer (golden set), and chatbot answer, like a question bank, to make sure we covered everything.

3. Writing a Script for Generating Answers
Once we made a bunch of questions, we wrote a script on the same sheet to help the chatbot answer the questions all by itself every time. The script is set up so that all we need to do is give it the name of the bot and the API we use to get answers. Through this method, we automated the process to generate the chatbot response to each question and added this answer to our “Chatbor Response” column. This helped us reduce the manual work. Now let’s move on to the last step.
4. Writing a script for answer comparison and report generation
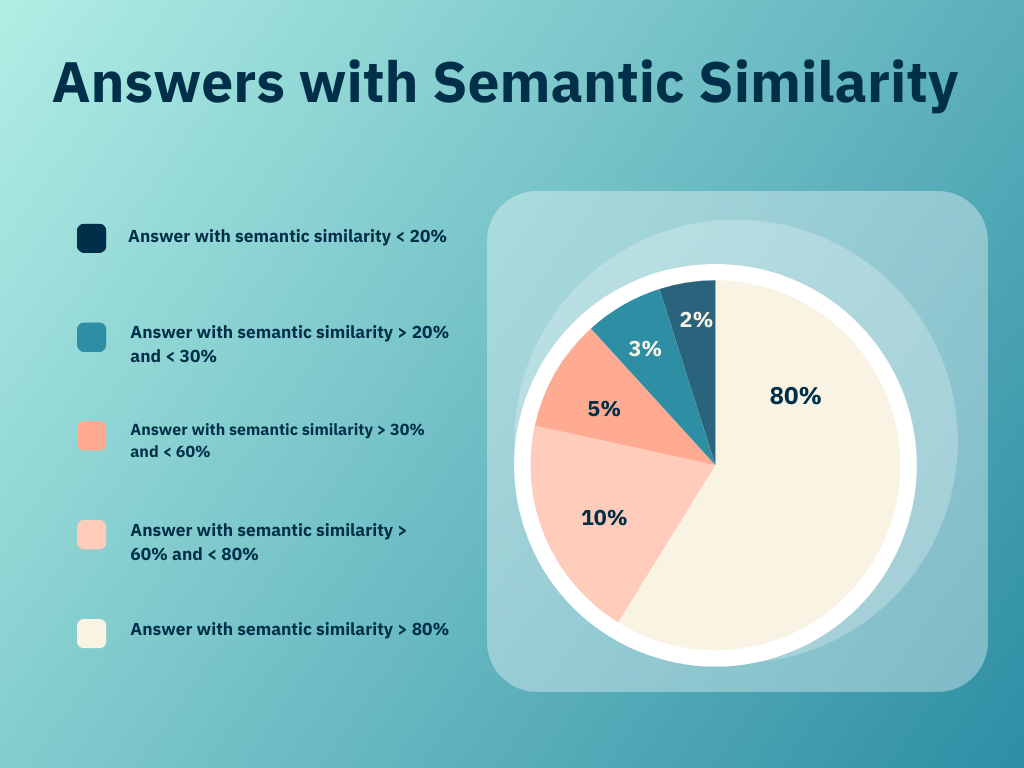
Our last step was to analyze and compare the answers generated by the bot. For this, we used different NLP models, like Bert and the Glove models. We wrote a script in which we used these models to generate the semantic similarity score. We saved the similarity score in a CSV sheet and used it to verify our chatbot response based on our cut-off score. These scores helped us understand and evaluate how much our bot is generating the correct answer.
You can find out more about our script through this GitHub repository.
Benefits of Automation Testing
- Reduced manual effort for generating and verifying answers: Automating the test helped us reduce our manual effort. Before automating our tests, we were checking and verifying our answers by hand. But now we can use our script to generate the answers and verify them, reducing manual effort by 70%.
- Report generation with semantic scores: Automation testing has improved our reporting a lot. Before, we could only say if answers were right or wrong during manual testing. But now, our automation script gives us detailed reports. These reports show scores for how close each answer is to what we expected. This helps us understand our testing results better and make smarter decisions.
- Time-saving: Previously, we spent almost two full days generating and validating answers manually. But, since automated testing, we’ve saved our time by nearly 90%. Now, we can complete our testing tasks, typically within a few hours.
- Quick Release Cycle: The automation has helped us with the quicker release of new versions by 40%. Now we can make changes in the bot, test them easily in a few hours instead of days, and release it.
Conclusion
In conclusion, we can see that automating our AI chatbot testing has made things much better for us. We’ve reduced manual effort by 70%, thanks to automated generation and verification of answers. Plus, our reports now show how close our chatbot’s answers are to what we expected, which helps us make smarter decisions. And we’re saving a ton of time too—almost 90%! Now, instead of taking two days to finish testing, we’re done in just a few hours. This big change shows how automation has really helped us work better and make our chatbots more reliable, improving the reputation of bots.
End Note
Thank you 🙌🏻 for joining us on this journey through our blog! We hope you find it informative and insightful ✨. Remember, the journey doesn’t end here. If you have any questions or feedback 💬, need further assistance, or want us to do the same work for you, don’t hesitate to reach out to us.
Further Readings
1. How Celebrity Chatbot Can Make Your Dreams Come True
2. How does automation improve quality for a business travel company?
3. Transforming Education: How We Automated Homework Workflows in an EdTech
4. Transforming Education: How GenAI Video Search Drove Ed Tech Growth
5. 30% Time Savings in AI Development: The EKS CI/CD Solution
6. How to Achieve 60% AWS Cost Optimization with Functions and Tags
7. Bot Deployment Challenges: How to Overcome in Production?
Follow Us
Madgical@LinkedIn
Madgical@Youtube
Madgical@Twitter
Disclaimer
The views are those of the author and are not necessarily endorsed by Madgical Techdom.